バスケットボールのベーシックスタッツ・アドバンスドスタッツまとめ
この間は、FIBA Basketball World Cup 2023のデータを使って、色んなデータ分析をしてみました。
ベーシックスタッツ+Four Factorsで各チームの特徴の表現を試みましたが、一つ、心残りがありました。 ディフェンスに関する指標が少なすぎでは?と。スティール・ブロック・ファール・ディフェンスリバウンドだけでは心許ないなと。
結果として、基本的には①シュート効率が良いか?、②リバウンドが強いか?の2点でほぼ表現されていた状態になってしまっていました。 そこで今回は、バスケットボールのスタッツを改めてまとめて、メモとして残すことにします。
そもそもスタッツとは?
バスケットボールの試合中におけるプレイを数値として記録したものがスタッツとなります。JBAが提唱しているゲームモデルに照らし合わせると、各プレイは次のような位置づけになるはずです(いわゆるベーシックスタッツ)。

オフェンストランジションからオフェンスに繋がり、オフェンスが終わったらディフェンスのトランジション・ディフェンスに繋がっていくという一連の流れを繰り返すことがバスケットボールという競技となります。
また、各プレイ単体だけでなく、チーム全体の特徴として、次のような要素も考えられます。
- オフェンス効率はよいか?→得点力はあるか?
- ディフェンス効率はよいか?→失点は少ないか?
- 試合のペースは速いか?→速攻主体か?ハーフコートオフェンス主体か?
単純な実数だけではなく、どれだけ有効なプレイが出来ているのかと言う観点からFour Factorsのようなアドバンスドスタッツも考案されています。

また、ディフェンスという観点では、相手側のオフェンススタッツを見れば、自分たちのディフェンスがどれだけ効いていたかをある程度把握することができるはずです。
ボックススコア・プレイヤースタッツ・チームスタッツの違い
一口にスタッツといっても、ゲーム別・チーム別・プレイヤー別に集計単位が異なったり、集計できるスタッツが変わってきます。特にデータ分析を行う上では、その違いは明確に切り分けておく必要があります。
次の図でいうと、白い箱の一つ一つがあるゲームでのプレイヤのスタッツ(=試合でのパフォーマンス)を示します。薄青い箱がチーム全体としてのスタッツを示すとします。

これをボックススコアや、プレイヤ平均スタッツ、チーム平均スタッツのような形に分類すると次のようになります。よくBリーグなどで、シーズン平均のスタッツでプレイヤのランキングが作られていますが、下の図でいくと大会があるシーズンに該当し、プレイヤ平均スタッツを元にランキングがつけられていることになります。

ベーシックスタッツ・アドバンスドスタッツまとめ
上記のようなことも踏まえながら、改めてどんなスタッツが存在するのかを一通りまとめてみました。特にチーム全体を分析するためのスタッツを重視してまとめています。 もちろん、他にも様々なあると思うので、適宜追加していけたらと思います。(タイムシェアをしているチームかどうかを、各選手の出場時間の平均・標準偏差で評価するなど?)
この考え方をベースにまた改めてデータ分析をしてみたいと思います。
| # | 大分類 | 中分類 | 表記 | 正式名称 | 概要 | プレイヤ粒度 | チーム粒度 |
| 1 | ベーシックスタッツ | 実数カウント | MIN | minutes | 出場時間 | ◯ | ◯ |
| 2 | PTS | points | 得点 | ◯ | ◯ | ||
| 3 | FG_MADE | field goal made | フィールドゴール成功数 | ◯ | ◯ | ||
| 4 | FG_ATTEMPT | field goal attempt | フィールゴール試投数 | ◯ | ◯ | ||
| 5 | 2P_MADE | 2 point made | 2P成功数 | ◯ | ◯ | ||
| 6 | 2P_ATTEMPT | 2 pont attempt | 2P試投数 | ◯ | ◯ | ||
| 7 | 3P_MADE | 3 point made | 3P成功数 | ◯ | ◯ | ||
| 8 | 3P_ATTEMPT | 3 point attempt | 3P試投数 | ◯ | ◯ | ||
| 9 | FT_MADE | free throw made | フリースロー成功数 | ◯ | ◯ | ||
| 10 | FT_ATTEMPT | free throw attempt | フリースロー試投数 | ◯ | ◯ | ||
| 11 | OREB | offensive rebound | オフェンスリバウンド数 | ◯ | ◯ | ||
| 12 | DREB | defensive rebound | ディフェンスリバウンド数 | ◯ | ◯ | ||
| 13 | REB | rebound | リバウンド総数 | ◯ | ◯ | ||
| 14 | AST | assist | アシスト数 | ◯ | ◯ | ||
| 15 | PF | personal foul | ファール数 | ◯ | ◯ | ||
| 16 | TO | turnover | ターンオーバー数 | ◯ | ◯ | ||
| 17 | ST | steal | スティール数 | ◯ | ◯ | ||
| 18 | BLK | block | ブロック | ◯ | ◯ | ||
| 19 | 割合 | FG% | field goal percentage | FG_MADE / FG_ATTEMPT | ◯ | ◯ | |
| 20 | 2P% | 2 point percentage | 2P_MADE / 2P_ATTEMPT | ◯ | ◯ | ||
| 21 | 3P% | 3 point percentage | 3P_MADE / 3P_ATTEMPT | ◯ | ◯ | ||
| 22 | FT% | free throw percentage | FT_MADE / FT_ATTEMPT | ◯ | ◯ | ||
| 23 | アドバンスドスタッツ | プレイヤ | +/- | plus minus | プレイヤが出場している時間中のチームでの得失点差 | ◯ | |
| 24 | EFF | efficiency | プレイヤのスタッツの総合評価の一種。(得点+リバウンド+アシスト+スティール+ブロック)- (シュートの失敗数+フリースローの失敗数+ターンオーバー) PTS + REB + AST + ST + BLK - ((FG_ATTEMPT - FG_MADE) + (FT_ATTEMPT + FT_MADE) + TO) |
◯ | |||
| 25 | チーム | POSS | posession | オフェンス回数。 FT_ATTEMPT * 0.44 + 2P_ATTEMPT + 3P_ATTEMPT + TO |
◯ | ||
| 26 | PACE | pace | 1試合40分あたりのオフェンス回数。試合時間は、5分延長の場合は40+5 = 45分となる。ただし、オフェンスリバウンド分はカウントしない。 (POSS - OREB) ÷ [試合時間] × 40 |
◯ | |||
| 27 | PPP | point per possesion | オフェンス1回あたりの得点期待値。 PTS ÷ POSS |
◯ | |||
| 28 | ORTG | offensive rating | オフェンス100回あたりの得点期待値。 PPP × 100 |
◯ | |||
| 29 | DRTG | defensive rating | ディフェンス100回あたりの失点期待値。 | ◯ | |||
| 30 | Four Factors | eFG% | effective field goal percentage | 3ポイントを考慮したフィールドゴール成功率。 (2P_MADE + 1.5 * 3P_MADE) / FG_ATTEMPT |
◯ | ||
| 31 | OREB% | offensive rebound percentage | オフェンスリバウンドの機会のうち、どれだけリバウンドを取れたか OREB / (OREB + OppDREB) |
◯ | |||
| 32 | FTR | free throw rate | どの程度フリースローを獲得できるか FT_ATTEMPT / FG_ATTEMPT |
◯ | |||
| 33 | TO% | turnover rate | オフェンス機会のうち、どれだけターンオーバーしているか TO / (FG_ATTEMPT + 0.44 * FT_ATTEMPT + TO) |
◯ | |||
| 34 | その他 | DREB% | deffensive rebound percentage | ディフェンスリバウンドの機会のうち、どれだけリバウンドを取れたか DREB / (DREB + OppOREB) |
◯ | ||
| 35 | OppPTS | opponent points | 相手の得点 | ◯ | |||
| 36 | OppFG_MADE | opponent field goal made | 相手のフィールドゴール成功数 | ◯ | |||
| 37 | OppFG_ATTEMPT | opponent field goal attempt | 相手のフィールゴール試投数 | ◯ | |||
| 38 | Opp2P_MADE | opponent 2 point made | 相手の2P成功数 | ◯ | |||
| 39 | Opp2P_ATTEMPT | opponent 2 pont attempt | 相手の2P試投数 | ◯ | |||
| 40 | Opp3P_MADE | opponent 3 point made | 相手の3P成功数 | ◯ | |||
| 41 | Opp3P_ATTEMPT | opponent 3 point attempt | 相手の3P試投数 | ◯ | |||
| 42 | OppFT_MADE | opponent free throw made | 相手のフリースロー成功数 | ◯ | |||
| 43 | OppFT_ATTEMPT | opponent free throw attempt | 相手のフリースロー試投数 | ◯ | |||
| 44 | OppOREB | opponent offensive rebound | 相手のオフェンスリバウンド数 | ◯ | |||
| 45 | OppDREB | opponent defensive rebound | 相手のディフェンスリバウンド数 | ◯ | |||
| 46 | OppREB | opponent rebound | 相手のリバウンド総数 | ◯ | |||
| 47 | OppAST | opponent assist | 相手のアシスト数 | ◯ | |||
| 48 | OppPF | opponent personal foul | 相手のファール数 | ◯ | |||
| 49 | OppTO | opponent turnover | 相手のターンオーバー数 | ◯ | |||
| 50 | OppST | opponent steal | 相手のスティール数 | ◯ | |||
| 51 | OppBLK | opponent block | 相手のブロック | ◯ | |||
| 52 | OppFG% | opponent field goal percentage | 相手のFG_MADE / FG_ATTEMPT | ◯ | |||
| 53 | Opp2P% | opponent 2 point percentage | 相手の2P_MADE / 2P_ATTEMPT | ◯ | |||
| 54 | Opp3P% | opponent 3 point percentage | 相手の3P_MADE / 3P_ATTEMPT | ◯ | |||
| 55 | OppFT% | opponent free throw percentage | 相手のFT_MADE / FT_ATTEMPT | ◯ |
参考にさせていただいた記事
Python+Seleniumを使ったスクレイピングその2(2023年10月時点)
この前はSeleniumを使ってスクレイピングを行い、ページソースを取得する部分までをメモとして残しました。今回は、さらにそのページソースから必要な部分を取得するやり方について、メモとして残しておきます。なお、今回もWindowsで行う前提です。
今回も例としてPythonの公式サイトにアクセスしてみます。公式サイトのトップページから、Latest Newsの各ページにアクセスし、本文を取得してデータフレームに格納することに挑戦してみます。
Webサイトへのアクセス
前回のおさらいですが、目的とするwebサイトにアクセスします。
# ライブラリをインポート from selenium import webdriver from selenium.webdriver.chrome.options import Options from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC # アクセスしたいURLを指定 url = "http://www.python.org" # ブラウザを操作するためのwebdriverを設定 options = Options() options.add_argument("--headless") driver = webdriver.Chrome(options=options) wait = WebDriverWait(driver=driver, timeout=30) # 最大待ち時間の設定 # ブラウザを起動し、URLにアクセス driver.get(url) wait.until(EC.presence_of_all_elements_located) # HTMLの要素が全てレンダリングされるまで待つ
ここで以下のように処理すると、あとはBeautifulSoupでHTMLを処理するだけになります。ただし、今回は勉強も兼ねてSeleniumだけでHTMLを処理し、必要な要素を取得してみようと思います。
from bs4 import BeautifulSoup def get_soup(driver): html = driver.page_source soup = BeautifulSoup(html, "html.parser") return soup soup = get_soup(driver)
HTMLを確認
実際にブラウザでWebサイトにアクセスし、処理したいHTMLの構造を確認しておきます。Chromeであれば、Ctrl + Shift +iでDevToolsを開き、WebサイトのHTMLを確認することが出来ます。右側のパネル上で、実際に取得したい要素の種類や、つけられているクラス名などを知ることが出来ます。

要素を取得
それでは、実際に要素を取得していきます。まずはLatest NewsのタイトルとURLの一覧を取得しておきます。
要素を取得する場合、次の2つのメソッドと、要素の指定方法、要素の中身(文章等)の取得方法を一つだけ覚えておけばなんとかなります。
要素の取得方法
取得する際のメソッドは次の通りです。
find_element()|要素を一つだけ取得します。同じ条件の要素が複数ある場合は最初の要素のみ取得します。find_elements()|条件に当てはまる要素を全て、リスト形式で取得します。
また、指定方法は次の通りです。
By.CSS_SELECTOR|要素の種類(div等)とclass名、あるいはid名で指定することが出来ます。ID名の場合は基本的に一要素にしかつけないので、find_element()としか組み合わせません。
class名で指定する場合、.を前につけて指定します。id名の場合は#です。なお、ある要素のさらに子要素を取得する場合は、直接の子要素であれば>、孫以降の要素も含むのであれば" "(※スペース)をつければOKです。
例えば、次のようなHTMLのページがあり、driverでアクセスしていたものとします。
<div id="id_name"> <p class="a_class">a_hoge</p> <p class="a_class">a_fuga</p> <p class="b_class">b_fuga</p> </div>
次のように指定することで、要素の取得が出来ます。
# id名で指定する場合 id_element = driver.find_element(By.CSS_SELECTOR, "div#id_name") # class名で指定する場合 a_class_element_list = driver.find_elements(By.CSS_SELECTOR, "p.a_class") # id名で指定した後、その下の子要素をまとめて指定する場合 p_element_list = driver.find_elements(By.CSS_SELECTOR, "div#id_name p")
要素の中身を取得する際には、get_attribute()を使います。aタグに対して行う場合、textContentを指定すれば文章を、hrefを指定すればURLを取得できます。
# 要素を取得 a_element = driver.find_element(By.CSS_SELECTOR, "a#sample_id") # 要素内の中身を取得 txt = a_alement.get_attribute("textContent") href = a_element.get_attribute("href")
タイトルとURLを取得
それでは、実際にLatest NewsのタイトルとURLを取得していきます。
# Latest NewsのタイトルとURLを取得する latest_news_elements_list = driver.find_elements(By.CSS_SELECTOR, "div.blog-widget li") latest_news_url_dict = {} for elem in latest_news_elements_list: # aタグを取得 a_tag = elem.find_element(By.CSS_SELECTOR, "a") # aタグから、タイトルとURLを取得 news_title = a_tag.get_attribute("textContent") news_url = a_tag.get_attribute("href") # dictに保存 latest_news_url_dict[news_title] = news_url print(latest_news_url_dict)
{'Announcing our new Community Communications Manager!': 'https://pyfound.blogspot.com/2023/10/announcing-community-communications-mgr.html', 'September & October Board Votes': 'https://pyfound.blogspot.com/2023/10/september-october-board-votes.html', 'Security Developer-in-Residence 2023 Q3 Report': 'https://pyfound.blogspot.com/2023/10/security-developer-in-residence-2023-q3-report.html', 'Python 3.13.0 alpha 1 is now available': 'https://pythoninsider.blogspot.com/2023/10/python-3130-alpha-1-is-now-available.html', 'Python 3.11.6 is now available': 'https://pythoninsider.blogspot.com/2023/10/python-3116-is-now-available.html'}
Latest Newsの本文を取得
それでは、実際に各URLにアクセスし、本文を取得していきます。要領は先程と同じです。各URLにアクセスする際、ちゃんと本文が表示されてから本文の取得を開始するように、WebDriverWait()を使っています。
import polars as pl # 各Latest NewsのURLにアクセスし、本文(pタグ)を取得する news_description_list = [] for title, url in latest_news_url_dict.items(): # URLにアクセス driver.get(url) WebDriverWait(driver, 30).until( EC.presence_of_element_located((By.CSS_SELECTOR, "div.post")) ) # 本文を取得(画像等が間に本文中に存在する影響で、複数のpタグに分かれていることに注意) description_elements = driver.find_elements(By.CSS_SELECTOR, "div.post p") description = "" for elem in description_elements: description += elem.get_attribute("textContent") # リストに保存 news_description_list.append(description) # データフレームに格納 latest_news_dict = { "title": latest_news_url_dict.keys(), "url": latest_news_url_dict.values(), "description": news_description_list } df = pl.from_dict(latest_news_dict) df.head()
shape: (5, 3)
| title | url | description |
|---|---|---|
| str | str | str |
| "Announcing our… | "https://pyfoun… | "We announced o… |
| "September & Oc… | "https://pyfoun… | "We’re writing … |
| "Security Devel… | "https://pyfoun… | "It’s been thre… |
| "Python 3.13.0 … | "https://python… | " It’s not a ve… |
| "Python 3.11.6 … | "https://python… | " Python 3.11.… |
しっかりと本文を取得し、データフレームに格納することが出来ました!
参考にさせていただいた記事
FIBA Basketball World Cup 2023をデータ分析してみた(Part.5|因子分析+k-meansクラスタリング)
本記事は、全5回に分けてFIBAバスケットボールワールドカップ2023の全92試合を分析してみたシリーズ第5回目です。
- 相関分析・可視化分析|勝敗と相関が高いスタッツの項目は何か?勝利したチームと敗北したチームのスタッツの差はどう違うのか?
- 決定木分析|勝利するチームのスタッツの条件は?(その1)
- LightGBM+SHAP分析|勝利するチームのスタッツの条件は?(その2)
- 次元削減分析(主成分分析・t-SNE・UMAP)|スタッツから見る大会参加チームの特徴は?(その1)
- 因子分析|スタッツから見る大会参加チームの特徴は?(その2)
前回は、主成分分析・t-SNE・UMAP等の手法から次元削減を行い、各チームを2次元にプロットしてみました。
今回は因子分析を行うことで、各チームの特徴をスコア化し、更にクラスタリングしてみることで、大会の参加チームの特徴がうまく分かれそうか?そして、日本はどのチームに似ていたのかを分析してみたいと思います。 前回の次元削減分析と因子分析はパッと見は似ていますが、ざっくりと以下のような違いがあります。雑ではありますが、計算の方向性が逆になっていると理解すると良いと思います。
- 次元削減分析|スタッツをいくつかのスコアに束ねる手法
- 因子分析|スタッツは、その背後にある因子が表面化したものであると捉え、スタッツから各因子を逆算する手法
※なお、クラスタリング自体は単体で行うことも、次元削減分析と組み合わせて行うこともできます。
目次は次の通りです。
データの準備・前処理
前回同様、大会公式サイトのデータから、因子分析用に前処理しておきます。
summary_team_df.head()
| TEAM | OREB | DREB | REB | AST | PF | TO | ST | BLK | FG_MADE | ... | DREB_OPPOSITE | eFG% | TO% | FTR | OREB% | 2PTS% | 3PTS% | FT% | RANK | TEAM_LABEL | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | ドイツ | -0.357255 | 0.654719 | 0.281435 | 0.767749 | -0.728020 | -1.242350 | 0.747780 | -0.651354 | 1.302677 | ... | -1.282535 | 1.265120 | -1.173782 | -0.376622 | 0.353542 | 1.389546 | 0.742347 | 0.727326 | 1 | 1_ドイツ |
| 1 | セルビア | -1.111176 | 0.213180 | -0.522665 | 1.171533 | -1.289234 | -1.378872 | 1.539473 | 0.057603 | 1.384190 | ... | -1.779762 | 1.705373 | -1.193995 | 0.922567 | -0.148243 | 2.132540 | 0.676955 | 0.596071 | 2 | 2_セルビア |
| 2 | カナダ | 0.739356 | 0.102796 | 0.535361 | 0.678020 | -0.104448 | -0.969306 | 0.351933 | -0.415035 | 1.343433 | ... | -0.835031 | 1.201705 | -1.224908 | 0.878006 | 1.096495 | 0.787233 | 1.174016 | 0.484411 | 3 | 3_カナダ |
| 3 | アメリカ合衆国 | -0.288717 | 2.200104 | 1.508746 | 1.261262 | -0.915091 | 0.395914 | 1.440512 | 2.420790 | 2.362344 | ... | -0.735585 | 1.481867 | -0.190144 | 1.239070 | 0.116469 | 1.307604 | 1.113105 | 0.795034 | 4 | 4_アメリカ合衆国 |
| 4 | ラトビア | -1.590943 | -0.228358 | -1.157481 | 1.440722 | 0.207337 | -1.651916 | -0.736646 | -0.060557 | 1.139651 | ... | -0.835031 | 1.693414 | -1.281602 | -1.751610 | -1.183893 | 1.218891 | 1.526417 | -0.100256 | 5 | 5_ラトビア |
5 rows × 27 columns
因子分析
それでは、実際に因子分析を行っていきます。因子分析用のライブラリをインポートしておきます。
poetry add factor_analyzer
因子数の決定
まずは因子数を仮置きしつつ、スクリープロットを描いて固有値を確認します。ガットマン基準より、固有値が1以上である数を因子数とします。 なお、回転法はプロマックス回転、母数推定には最尤法を指定しておきます。
from factor_analyzer import FactorAnalyzer feature_cols = [ 'OREB', 'DREB', 'AST', 'PF', 'TO', 'ST', 'BLK', '2PTS_ATTEMPT', '3PTS_ATTEMPT', 'FT_ATTEMPT', 'eFG%', 'TO%', 'FTR', 'OREB%', '2PTS%', '3PTS%', 'FT%', ]
N = 2 # 仮置き X = summary_team_df[feature_cols] embedded_cols = [f"embedded_{i+1}" for i in range(N)] # 因子分析の実行 fa = FactorAnalyzer(n_factors=N, rotation="promax", method="ml") fa.fit(X) # スクリープロットによる因子数の確認(ガットマン基準の場合、固有値1以上の因子を採用) eigen_values = fa.get_eigenvalues() eigen_x = list(range(1, len(eigen_values[0])+1)) print("スクリープロット") plt.figure(figsize=(12, 8)) plt.plot(eigen_x, eigen_values[0], marker="o") plt.hlines(y=1, xmin=0, xmax=20, linestyles="dashed") plt.ylabel("固有値") plt.title("スクリープロット") plt.show()

因子数は6因子を想定することにします。
因子負荷量の確認
それでは、6因子を仮定して、因子分析を進めていきます。まずは因子負荷量を確認し、各因子がどのような因子なのかを解釈していきます。
N = 6 # 因子分析の実行 fa = FactorAnalyzer(n_factors=N, rotation="promax", method="ml") fa.fit(X) # 因子負荷量の確認 loading_df = pd.DataFrame(fa.loadings_, columns=embedded_cols, index=feature_cols) plt.figure(figsize=(12, 8)) sns.heatmap(loading_df, cmap="coolwarm", annot=True, fmt=".2f") plt.title("因子負荷量") plt.show()

絶対値が比較的大きいスタッツを見比べてみると、各因子は次のような意味を持っているようです。
- embedded_1|この因子が高いとTOが増える。TOのしやすさ
- embedded_2|この因子が高いとDREB・BLK・2PTS%が高くなる。また、PFが少なくなる。インサイドの強さ(高さ?)
- embedded_3|この因子が高いとFTが増える。FTの多さ
- embedded_4|この因子が高いとAST・eFG%・3PTS%が高くなる。シュート効率の良さ
- embedded_5|この因子が高いとOREBが増える。OREBのアグレッシブさ
- embedded_6|この因子が高いと2PTS_ATTEMPTが増え、2PTS%が小さくなる。2PTS偏重
寄与率の確認
各因子の寄与率も見ておきます。
# 因子寄与・因子寄与率・累積寄与率の確認 variance_df = pd.DataFrame(fa.get_factor_variance(), index=["因子寄与", "因子寄与率", "累積寄与率"], columns=embedded_cols) print("因子の寄与") display(variance_df)
| embedded_1 | embedded_2 | embedded_3 | embedded_4 | embedded_5 | embedded_6 | |
|---|---|---|---|---|---|---|
| 因子寄与 | 2.333270 | 2.329368 | 2.206963 | 2.155444 | 1.918768 | 1.009655 |
| 因子寄与率 | 0.137251 | 0.137022 | 0.129821 | 0.126791 | 0.112869 | 0.059391 |
| 累積寄与率 | 0.137251 | 0.274273 | 0.404094 | 0.530885 | 0.643754 | 0.703145 |
6因子で元のスタッツの分散の約7割を説明できているようです。
因子得点の確認
それでは、各チームの因子得点を取得します。この得点を元に、クラスタリングにかけていきます。
# 因子得点の確認 score_df = pd.DataFrame(fa.transform(X), columns=embedded_cols, index=label_txt) print("因子得点") display(score_df)
| embedded_1 | embedded_2 | embedded_3 | embedded_4 | embedded_5 | embedded_6 | |
|---|---|---|---|---|---|---|
| 1_ドイツ | -1.300328 | 1.179297 | -0.244862 | 0.934883 | 0.062245 | -0.555002 |
| 2_セルビア | -1.372017 | 1.672746 | 0.926903 | 1.157072 | -0.625907 | -1.059549 |
| 3_カナダ | -1.262478 | 0.699717 | 1.095309 | 1.279031 | 1.028844 | 0.151513 |
| 4_アメリカ合衆国 | 0.126095 | 1.976963 | 1.630710 | 1.190871 | -0.092600 | 1.740469 |
| 5_ラトビア | -1.518292 | 0.978369 | -1.650575 | 1.576361 | -1.171244 | -1.346630 |
| 6_リトアニア | -0.586678 | 0.313404 | -0.603971 | 1.413674 | 0.967860 | -0.782937 |
| 7_スロベニア | -0.198929 | 0.079474 | 1.652097 | 0.567348 | 0.190069 | -1.185422 |
| 8_イタリア | -0.696013 | -0.022033 | -0.969312 | -0.908474 | 0.382515 | 0.201561 |
| 9_スペイン | -0.262429 | 0.187576 | 0.731657 | 0.665695 | 1.153473 | -1.247843 |
| 10_オーストラリア | -0.727880 | 1.143794 | -0.344179 | 0.560399 | 0.050008 | 0.692050 |
| 11_モンテネグロ | -0.058929 | -0.084426 | -0.560019 | -1.193360 | 1.423290 | 0.881684 |
| 12_プエルトリコ | 0.336869 | -0.224440 | 0.255571 | 0.553201 | 0.560770 | 1.336374 |
| 13_ブラジル | -0.672562 | -0.034382 | 0.173693 | -0.153772 | 0.611894 | -0.775313 |
| 14_ドミニカ共和国 | 0.263081 | -0.395316 | 1.087932 | -0.281374 | 0.038062 | 0.730990 |
| 15_ギリシャ | -2.009215 | -0.669822 | -0.929280 | -0.335854 | -0.418754 | -0.328830 |
| 16_ジョージア | 2.026440 | -0.117894 | 0.085884 | -0.946016 | -0.714204 | -0.143693 |
| 17_南スーダン | -0.997016 | -0.194253 | 0.721846 | 1.198105 | -0.699037 | -0.061825 |
| 18_フランス | 1.409952 | 1.476136 | 0.072627 | 0.247088 | 0.818498 | -1.355281 |
| 19_日本 | 0.440371 | 0.691697 | 0.025749 | -0.502517 | -1.569685 | 0.496960 |
| 20_エジプト | 1.270005 | 1.105493 | 0.038276 | -0.730704 | 0.257615 | 1.372383 |
| 21_フィンランド | 0.877145 | 0.869527 | -1.176184 | 0.181314 | 0.793089 | -0.368637 |
| 22_ニュージーランド | 1.515544 | -1.078821 | 1.044124 | 0.679003 | 0.057723 | 0.652533 |
| 23_レバノン | 1.011710 | -0.440044 | -0.682162 | 0.759718 | -0.776703 | -1.314634 |
| 24_フィリピン | 0.716270 | 0.270888 | -0.226830 | -0.901639 | 0.086573 | 1.068112 |
| 25_メキシコ | 0.348967 | -0.738434 | -0.253861 | 0.388717 | -1.425465 | 0.286682 |
| 26_アンゴラ | -0.927790 | -1.298743 | 1.633542 | -2.649551 | 2.652439 | 1.937343 |
| 27_コートジボワール | -0.396090 | -2.066069 | -0.838843 | -0.199135 | -1.093058 | -0.474282 |
| 28_カーボベルデ | 0.556580 | -0.601142 | -0.107800 | -1.750730 | 1.098031 | 1.293462 |
| 29_中国 | 0.407826 | -0.535705 | 0.668903 | -0.338006 | -2.390146 | -1.115700 |
| 30_ベネズエラ | 0.112124 | -0.796972 | -2.586102 | -0.156477 | -0.036876 | -0.534536 |
| 31_イラン | -0.195358 | -2.133336 | -1.545377 | -1.431229 | -0.239887 | -0.737360 |
| 32_ヨルダン | 1.763028 | -1.213248 | 0.874536 | -0.873640 | -0.979431 | 0.545358 |
クラスタリング
それではクラスタリングを行っていきます。今回はk-means++という手法を用いていきます。まず最初に、クラスタ数を決める必要があるため、エルボー法とシルエット法の2つの手法から、適切なクラスタ数を判別していきます。
エルボー法の場合は折れ線グラフがガクッと落ちこむあたりをクラスタ数として設定します。また、シルエット法の場合は、各クラスタのシルエットが綺麗に分かれて描画されたクラスタ数を採用します。
# クラスタリング用ライブラリ from sklearn.cluster import KMeans from sklearn.metrics import silhouette_samples # シルエット法の描画用関数 def show_silhouette(X, fitted_model): cluster_labels = np.unique(fitted_model.labels_) num_clusters = cluster_labels.shape[0] silhouette_vals = silhouette_samples(X, fitted_model.labels_) # シルエット係数の計算 # 可視化 y_ax_lower, y_ax_upper = 0, 0 y_ticks = [] for idx, cls in enumerate(cluster_labels): cls_silhouette_vals = silhouette_vals[fitted_model.labels_==cls] cls_silhouette_vals.sort() y_ax_upper += len(cls_silhouette_vals) cmap = cm.get_cmap("Spectral") rgba = list(cmap(idx/num_clusters)) # rgbaの配列 rgba[-1] = 0.7 # alpha値を0.7にする plt.barh( y=range(y_ax_lower, y_ax_upper), width=cls_silhouette_vals, height=1.0, edgecolor='none', color=rgba) y_ticks.append((y_ax_lower + y_ax_upper) / 2.0) y_ax_lower += len(cls_silhouette_vals) silhouette_avg = np.mean(silhouette_vals) plt.axvline(silhouette_avg, color='orangered', linestyle='--') plt.xlabel('silhouette coefficient') plt.ylabel('cluster') plt.yticks(y_ticks, cluster_labels + 1) plt.show() # 2~10のクラスタ数でクラスタリング sse_list = [] # エルボー法用 min_n = 2 max_n = 10 for i in range(min_n, max_n): model = KMeans(n_clusters=i, random_state=0, init="k-means++") model.fit(score_df) sse_list.append(model.inertia_) show_silhouette(score_df.to_numpy(), model) # シルエット法 plt.plot(range(min_n, max_n), sse_list, marker="o") plt.xlabel("number of cluseters") plt.ylabel("sum of squared errors") plt.title("エルボー法") plt.show()

まず、エルボー法から見てみるとなんとも言えない結果となりました。




次に、シルエット法です。一部結果を抜粋しています。こちらもなんとも言えない結果ではありますが、クラスタ数3が一番きれいにシルエットが出ているため、今回はクラスタ数3を採用することにします。
さて、それでは実際にクラスタリングを行い、結果を解釈していきます。
# クラスタ数3に設定 model = KMeans(n_clusters=3, random_state=0, init="k-means++") model.fit(score_df) score_df["cluster"] = model.predict(score_df) score_df["cluster_str"] = score_df["cluster"].astype("str") # 箱ひげ図のプロット用にクラスタの値を文字列化 # クラスタごとの因子得点の分布を確認 n_rows = 2 n_cols = 3 fig, axes = plt.subplots(nrows=n_rows, ncols=n_cols, figsize=(10, 10), tight_layout=True) for idx, col in enumerate(embedded_cols): i = idx // n_cols j = idx % n_cols sns.boxplot(x=col, y="cluster_str", data=score_df, ax=axes[i, j]) axes[i, j].set_title(f"{col} x クラスタ") plt.show() score_df = score_df.drop("cluster_str", axis=1) # 以後不要なため、削除

ここで、先程解釈した各因子の情報を再掲しておきます。
- embedded_1|この因子が高いとTOが増える。TOのしやすさ
- embedded_2|この因子が高いとDREB・BLK・2PTS%が高くなる。また、PFが少なくなる。インサイドの強さ(高さ?)
- embedded_3|この因子が高いとFTが増える。FTの多さ
- embedded_4|この因子が高いとAST・eFG%・3PTS%が高くなる。シュート効率の良さ
- embedded_5|この因子が高いとOREBが増える。OREBのアグレッシブさ
- embedded_6|この因子が高いと2PTS_ATTEMPTが増え、2PTS%が小さくなる。2PTS偏重
こうして各クラスタごとに因子の違いを見てみると、
- クラスタ0|embedded_1(TOの多さ)とembedded_6(2PTS偏重)が高く、embedded_4(シュート効率の良さ)が低いです。ミスが多く、2PTS偏重でシュートの効率が悪いということで、うまく得点ができずに苦しんだチーム(≒下位チーム)が含まれているであろうと解釈できそうです。
- クラスタ1|基本的にはどの因子でも平均的な値を残していそうです。強いて言うなら、embedded_2(インサイドの強さ?)とembedded_3(FTの多さ)がやや低いので、インサイドで苦労し、FTでの得点が少なかったチームが多そうです。
- クラスタ2|クラスタ2はembedded_4(シュート効率の良さ)が高く、しっかりと得点を稼いだ上位チームが入っていそうです。
それでは、上記の情報を踏まえ、具体的にどのチームがどのクラスタだったかを因子得点と共に見ていきます。
# クラスタ数と因子得点 score_df = score_df.sort_values(by="cluster") plt.figure(figsize=(12, 8)) sns.heatmap(score_df, cmap="coolwarm", annot=True, fmt=".2f") plt.title("クラスタ別因子得点") plt.show()

事前の解釈通り、クラスタ0は下位リーグに回ったチームが多く、クラスタ2が上位チーム、クラスタ1がその中間という結果になりました。
今回の分析結果としては、日本はクラスタ0に分類されていますが、ヒートマップの色を見てもクラスタ0の中では少し特殊な因子得点となっている(embedded_2が高く、embedded_5が小さい等)ため、クラスタ0ど真ん中という感じではなさそうです。
まとめ
因子分析からクラスタリングまでの一連の流れを通して、参加チームの特徴を分析しました。やはり、一貫してミスが少なく、効率の良いシュートを打てているチームが上位チームに入っているということが、改めて今回の分析からもあらわになりました。
今回でFIBA Basketball World Cup 2023の分析は一段落しました。今後は、他のアドバンスドスタッツも分析対象に含める、他の大会・リーグでも分析してみるなど気が向いたら色々とやっていきたいと思います。
参考にさせていただいた記事
FIBA Basketball World Cup 2023をデータ分析してみた(Part.4|次元削減分析(主成分分析・t-SNE・UMAP))
本記事は、全5回に分けてFIBAバスケットボールワールドカップ2023の全92試合を分析してみたシリーズ第4回目です。
- 相関分析・可視化分析|勝敗と相関が高いスタッツの項目は何か?勝利したチームと敗北したチームのスタッツの差はどう違うのか?
- 決定木分析|勝利するチームのスタッツの条件は?(その1)
- LightGBM+SHAP分析|勝利するチームのスタッツの条件は?(その2)
- 次元削減分析(主成分分析・t-SNE・UMAP)|スタッツから見る大会参加チームの特徴は?(その1)
- 因子分析+クラスタリング|スタッツから見る大会参加チームの特徴は?(その2)
前回・前々回は、決定木分析やLightGBM+SHAP分析を行い、勝利する際のスタッツの条件を探ってみました。 bballdatanote.hatenablog.com
今回は主成分分析やt-SNE、UMAPなどの手法を用いて各チームのスタッツを2次元に落とし込み、プロットしてみることで、大会の参加チームの特徴がうまく分かれそうか?そして、日本はどのチームに似ていたのかを分析してみたいと思います。
目次は次の通りです。
データの準備・前処理
毎回同様、大会公式サイトのデータを用いて、以下のように試合別・チーム別のデータに集約していきます。また、追加スタッツとしてFour FactorsとField Goal Percentageも出しておきます。
team_df.head()
| GAME_KEY | TEAM | GAME_POSITION | RESULT | OREB | DREB | REB | AST | PF | TO | ST | BLK | FG_MADE | FG_ATTEMPT | 2PTS_MADE | 2PTS_ATTEMPT | 3PTS_MADE | 3PTS_ATTEMPT | FT_MADE | FT_ATTEMPT | eFG% | TO% | FTR | DREB_OPPOSITE | OREB% | 2PTS% | 3PTS% | FT% | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 試合日1_ドイツ_日本 | 日本 | right | LOSE | 6 | 24 | 30 | 17 | 16 | 12 | 5 | 3 | 23 | 65 | 17 | 30 | 6 | 35 | 11 | 17 | 0.400000 | 0.142045 | 0.261538 | 36 | 0.142857 | 0.566667 | 0.171429 | 0.647059 |
| 1 | 試合日1_南スーダン_プエルトリコ | 南スーダン | left | LOSE | 8 | 27 | 35 | 23 | 23 | 19 | 9 | 5 | 34 | 67 | 24 | 41 | 10 | 26 | 18 | 24 | 0.582090 | 0.196769 | 0.358209 | 26 | 0.235294 | 0.585366 | 0.384615 | 0.750000 |
| 2 | 試合日1_スペイン_コートジボワール | スペイン | left | WIN | 14 | 28 | 42 | 29 | 14 | 17 | 7 | 5 | 34 | 64 | 23 | 35 | 11 | 29 | 15 | 22 | 0.617188 | 0.187472 | 0.343750 | 16 | 0.466667 | 0.657143 | 0.379310 | 0.681818 |
| 3 | 試合日2_オーストラリア_ドイツ | ドイツ | right | WIN | 5 | 20 | 25 | 18 | 19 | 12 | 9 | 3 | 31 | 61 | 20 | 31 | 11 | 30 | 12 | 15 | 0.598361 | 0.150754 | 0.245902 | 22 | 0.185185 | 0.645161 | 0.366667 | 0.800000 |
| 4 | 試合日2_レバノン_カナダ | レバノン | left | LOSE | 6 | 10 | 16 | 19 | 18 | 22 | 12 | 1 | 30 | 62 | 22 | 43 | 8 | 19 | 5 | 5 | 0.548387 | 0.255220 | 0.080645 | 24 | 0.200000 | 0.511628 | 0.421053 | 1.000000 |
また、今回はプロットする際の参考情報として大会の順位も使うことにします。
rank_df.head()
さらに、これまではチーム別・試合別の粒度でデータを扱ってきましたが、今回はチーム別の粒度で分析します。また、次元削減分析を行うにあたっては、標準化をかけて各スタッツのスケールを合わせておきます(より適切に次元削減を行い、解釈しやすくするため)。そのため、以下のような前処理を行っていきます。
# 実数系(割合ではない)スタッツ basic_stats_cols = [ 'OREB', 'DREB', 'REB', 'AST', 'PF', 'TO', 'ST', 'BLK', 'FG_MADE', 'FG_ATTEMPT', '2PTS_MADE', '2PTS_ATTEMPT', '3PTS_MADE', '3PTS_ATTEMPT', 'FT_MADE', 'FT_ATTEMPT', 'DREB_OPPOSITE', ]
# チームごとに実数系のスタッツの試合平均を取る summary_team_df = team_df.group_by("TEAM").agg(pl.mean(basic_stats_cols)) # シュート成功率等の割合系のスタッツを計算 summary_team_df = process_team_stats(summary_team_df, key_cols=["TEAM"]) # 大会の最終順位と突合し、国名に最終順位を結合(可視化用に利用) summary_team_df = summary_team_df.join( rank_df, on="TEAM", how="left" ).with_columns( TEAM_LABEL=pl.col("RANK").cast(str) + "_" + pl.col("TEAM") ).sort( "RANK" ).to_pandas() # 次元削減用に標準化 scale_cols = [col for col in summary_team_df.columns if not col in ["TEAM_LABEL", "TEAM", "RANK"]] # 標準化する対象のスタッツの一覧 scaler = ColumnTransformer([ ("Standard Scaler", StandardScaler(), scale_cols) ]) scaler.fit(summary_team_df[scale_cols]) summary_team_df[scale_cols] = scaler.transform(summary_team_df[scale_cols]) summary_team_df.head()
| TEAM | OREB | DREB | REB | AST | PF | TO | ST | BLK | FG_MADE | ... | DREB_OPPOSITE | eFG% | TO% | FTR | OREB% | 2PTS% | 3PTS% | FT% | RANK | TEAM_LABEL | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | ドイツ | -0.357255 | 0.654719 | 0.281435 | 0.767749 | -0.728020 | -1.242350 | 0.747780 | -0.651354 | 1.302677 | ... | -1.282535 | 1.265120 | -1.173782 | -0.376622 | 0.353542 | 1.389546 | 0.742347 | 0.727326 | 1 | 1_ドイツ |
| 1 | セルビア | -1.111176 | 0.213180 | -0.522665 | 1.171533 | -1.289234 | -1.378872 | 1.539473 | 0.057603 | 1.384190 | ... | -1.779762 | 1.705373 | -1.193995 | 0.922567 | -0.148243 | 2.132540 | 0.676955 | 0.596071 | 2 | 2_セルビア |
| 2 | カナダ | 0.739356 | 0.102796 | 0.535361 | 0.678020 | -0.104448 | -0.969306 | 0.351933 | -0.415035 | 1.343433 | ... | -0.835031 | 1.201705 | -1.224908 | 0.878006 | 1.096495 | 0.787233 | 1.174016 | 0.484411 | 3 | 3_カナダ |
| 3 | アメリカ合衆国 | -0.288717 | 2.200104 | 1.508746 | 1.261262 | -0.915091 | 0.395914 | 1.440512 | 2.420790 | 2.362344 | ... | -0.735585 | 1.481867 | -0.190144 | 1.239070 | 0.116469 | 1.307604 | 1.113105 | 0.795034 | 4 | 4_アメリカ合衆国 |
| 4 | ラトビア | -1.590943 | -0.228358 | -1.157481 | 1.440722 | 0.207337 | -1.651916 | -0.736646 | -0.060557 | 1.139651 | ... | -0.835031 | 1.693414 | -1.281602 | -1.751610 | -1.183893 | 1.218891 | 1.526417 | -0.100256 | 5 | 5_ラトビア |
5 rows × 27 columns
次元削減分析
それでは、実際に次元削減分析を行っていきます。今回試すのは、主成分分析(PCA)・t-SNE・UMAP、そして主成分分析(PCA)+UMAPの2段階で次元削減を行うパターンの計4種類です。※参考記事は最後に載せています。
なお、UMAPは事前にインストールしておきます。
poetry add umap
関数の準備
似たようなことを繰り返し行うため、予め関数として定義しておきます。なお、主成分分析(PCA)のみは線形的なアルゴリズムのため、各スタッツに係数(ローディング)を乗じて足したものが次元削減後の値となるため、係数(ローディング)を表示させるようにしておきます。他のアルゴリズムは非線形的なアルゴリズムのため、別のやり方で元のスタッツと次元削減後の値の関係性を考察するようにします。
# ライブラリのインポート # 可視化系 import matplotlib.pyplot as plt import seaborn as sns import japanize_matplotlib %matplotlib inline # 特徴量エンジニアリング・モデル評価系 from sklearn.compose import ColumnTransformer from sklearn.preprocessing import StandardScaler # 次元圧縮系 from sklearn.decomposition import PCA from sklearn.manifold import TSNE from umap import UMAP
# 次元削減対象のスタッツ feature_cols = [ 'OREB', 'DREB', 'AST', 'PF', 'TO', 'ST', 'BLK', '2PTS_ATTEMPT', '3PTS_ATTEMPT', 'FT_ATTEMPT', 'eFG%', 'TO%', 'FTR', 'OREB%', '2PTS%', '3PTS%', 'FT%', ]
次元削減用のサブ関数(ここをクリックすると表示されます)
# 次元削減モデルを設定する def embedding_models(model_name, N): embedding_model_dict = { "PCA": PCA(n_components=N, random_state=0), "tSNE": TSNE(n_components=N, random_state=0), "UMAP": UMAP(n_components=N, random_state=0) } return embedding_model_dict[model_name] # 実際に次元削減を行い、結果として次元削減モデルと次元削減後の結果を返す def embedding(X, model_name, N, embedded_cols, label_txt): model = embedding_models(model_name, N) X_embedded = model.fit_transform(X) embedded_df = ( pl.DataFrame(X_embedded, schema=embedded_cols) .with_columns(TEAM_LABEL=pl.lit(label_txt)) ) return model, embedded_df.to_pandas() # 次元削減した結果をプロットする def plot_embedded_space(model_name, embedded_df, size): print("次元削減空間の可視化") plt.figure(figsize=(12, 8)) sns.scatterplot(x="embedded_1", y="embedded_2", data=embedded_df, hue=embedded_df["TEAM_LABEL"], size=size, palette=sns.color_palette("coolwarm", 32), sizes=(20, 200)) for x, y, txt in zip(embedded_df["embedded_1"], embedded_df["embedded_2"], embedded_df["TEAM_LABEL"]): plt.text(x, y, txt, size=10) plt.title(f"Emmbedding Space {model_name}") plt.xlabel("embedded_1") plt.ylabel("embedded_2") plt.legend(embedded_df["TEAM_LABEL"], loc='center left', bbox_to_anchor=(1., .5)) plt.show() # 次元削減した結果をチームごとに棒グラフで表示する def show_embedded_score(embedded_df, embedded_cols): embedded_df = pl.from_pandas(embedded_df)[["TEAM_LABEL"]+embedded_cols] print("スコア") display(embedded_df) plt.figure(figsize=(6, 20)) embedded_df = embedded_df.melt(id_vars="TEAM_LABEL", value_vars=embedded_cols).to_pandas() sns.barplot(x="value", y="TEAM_LABEL", data=embedded_df, hue="variable", palette=sns.color_palette("deep")) plt.axvline(x=0, color="lightgray", linestyle="--") plt.show() # (PCAのみ)次元削減した結果と各スタッツの関係性(係数/ローディング)を表示・プロットする def show_loading(model, feature_cols, embedded_cols): loading_df = pd.DataFrame(model.components_.T, index=feature_cols, columns=embedded_cols) x_col = embedded_cols[0] y_col = embedded_cols[1] print("ローディング") display(loading_df) plt.figure(figsize=(8, 8)) sns.scatterplot(x=x_col, y=y_col, data=loading_df) for x, y, txt in zip(loading_df[x_col], loading_df[y_col], loading_df.index): plt.text(x, y, txt, size=10) plt.show() # (PCA以外)次元削減した結果と、各スタッツの関係性を相関係数、散布図で可視化する def plot_embedded_score_vs_features(summary_team_df, embedded_df, feature_cols, embedded_cols): tmp_df = embedded_df.merge(summary_team_df, on="TEAM_LABEL", how="left") n_rows = 5 n_cols = 4 for embedded in embedded_cols: # 相関係数 corr_cols = feature_cols + [embedded] corr_df = (pl.from_pandas(tmp_df[corr_cols]) .corr() .with_columns(INDEX_COL=pl.Series(corr_cols)) .to_pandas() .set_index("INDEX_COL") ) plt.figure(figsize=(12, 8)) sns.heatmap(corr_df, cmap="coolwarm", vmin=-1, vmax=1, square=True, annot=True, fmt=".2f") plt.show() # 散布図で可視化 fig, axes = plt.subplots(nrows=n_rows, ncols=n_cols, figsize=(24, 24), tight_layout=True) for idx, feature in enumerate(feature_cols): i = idx // n_cols j = idx % n_cols sns.scatterplot(x=feature, y=embedded, data=tmp_df, hue=tmp_df["TEAM_LABEL"], palette=sns.color_palette("coolwarm", 32), ax=axes[i, j]) for x, y, txt in zip(tmp_df[feature], tmp_df[embedded], tmp_df["TEAM_LABEL"]): axes[i, j].text(x, y, txt, size=8) axes[i, j].set_title(f"{embedded} X {feature}") axes[i, j].get_legend().remove() plt.show() print("-"*100)
次元削減用のメイン関数(ここをクリックすると表示されます)
# 実際に次元削減、可視化を行っていく(PCA・t-SNE・UMAP用) def summary_embedding(summary_team_df, model_name, N, feature_cols, label_col, size_col): X = summary_team_df[feature_cols] label_txt = summary_team_df[label_col].to_list() size = summary_team_df[size_col].to_list() embedded_cols = [f"embedded_{i+1}" for i in range(N)] # 次元削減 model, embedded_df = embedding(X=X, model_name=model_name, N=N, embedded_cols=embedded_cols, label_txt=label_txt) # 次元削減後の可視化 plot_embedded_space(model_name=model_name, embedded_df=embedded_df, size=size) print("#"*200) # 次元削減結果のスコアの可視化 show_embedded_score(embedded_df=embedded_df, embedded_cols=embedded_cols) print("#"*200) # スコアと特徴量の可視化(PCAの場合はローディング、それ以外は相関係数+散布図) if model_name == "PCA": show_loading(model=model, feature_cols=X.columns, embedded_cols=embedded_cols) else: plot_embedded_score_vs_features(summary_team_df=summary_team_df, embedded_df=embedded_df, feature_cols=feature_cols, embedded_cols=embedded_cols) print("#"*200) # 実際に次元削減、可視化を行っていく(PCA+UMAP用) def summary_embedding_pca_umap(summary_team_df, model_name, pca_N, umap_N, feature_cols, label_col, size_col): X = summary_team_df[feature_cols] label_txt = summary_team_df[label_col].to_list() size = summary_team_df[size_col].to_list() pca_embedded_cols = [f"embedded_{i+1}" for i in range(pca_N)] embedded_cols = [f"embedded_{i+1}" for i in range(umap_N)] # 次元削減 pca_model, pca_embedded_df = embedding(X=X, model_name="PCA", N=pca_N, embedded_cols=pca_embedded_cols, label_txt=label_txt) model, embedded_df = embedding(X=pca_embedded_df[pca_embedded_cols], model_name="UMAP", N=umap_N, embedded_cols=embedded_cols, label_txt=label_txt) # 次元削減後の可視化 plot_embedded_space(model_name=model_name, embedded_df=embedded_df, size=size) print("#"*200) # 次元削減結果のスコアの可視化 show_embedded_score(embedded_df=embedded_df, embedded_cols=embedded_cols) print("#"*200) # スコアと特徴量の可視化(PCAの場合はローディング、それ以外は相関係数+散布図) if model_name == "PCA": show_loading(model=model, feature_cols=X.columns, embedded_cols=embedded_cols) else: plot_embedded_score_vs_features(summary_team_df=summary_team_df, embedded_df=embedded_df, feature_cols=feature_cols, embedded_cols=embedded_cols) print("#"*200)
それでは、実際に次元削減を行っていきます。
主成分分析(PCA)
まずは主成分分析(PCA)からです。
summary_embedding(
summary_team_df=summary_team_df,
model_name="PCA",
N=2,
label_col="TEAM_LABEL",
size_col="RANK",
feature_cols=feature_cols
)
次元削減空間の可視化
 なんとなく右側が下位チーム、左側が上位チームに分かれています。左上のラトビアと左下のアメリカ合衆国は特徴的なものがあるのでしょうか。
なんとなく右側が下位チーム、左側が上位チームに分かれています。左上のラトビアと左下のアメリカ合衆国は特徴的なものがあるのでしょうか。
日本はドイツ・フィンランド・ブラジルと近い場所にプロットされていますね。次に、次元削減後のスコア(embedded_1とembedded_2)を棒グラフでもプロットしてみます。
次元削減結果のスコアの可視化

先程の散布図の例を棒グラフとして表示しただけです。上位チームだと青色のembedded_1はマイナス、下位チームだとマイナスとなっている傾向であることが見て取れます。更に、各スコアの意味を解釈していきます。
スコアと特徴量の可視化(PCAの場合なのでローディング)
係数の実際の値は次の通りです。
| embedded_1 | embedded_2 | |
|---|---|---|
| OREB | 0.221202 | -0.216115 |
| DREB | -0.179890 | -0.375490 |
| AST | -0.385786 | -0.059124 |
| PF | 0.287357 | 0.064920 |
| TO | 0.178229 | -0.264742 |
| ST | 0.077950 | -0.143391 |
| BLK | -0.177066 | -0.332815 |
| 2PTS_ATTEMPT | 0.191240 | -0.240046 |
| 3PTS_ATTEMPT | -0.167807 | 0.243864 |
| FT_ATTEMPT | 0.031401 | -0.425537 |
| eFG% | -0.451049 | -0.080173 |
| TO% | 0.147900 | -0.179360 |
| FTR | 0.016320 | -0.408268 |
| OREB% | 0.016784 | -0.267625 |
| 2PTS% | -0.395949 | -0.158122 |
| 3PTS% | -0.368141 | 0.045435 |
| FT% | -0.184991 | 0.032140 |
さらに散布図にプロットしてみます。

どうやら、主成分分析(PCA)においては、
- embedded_1|PF・OREB・2PTS_ATTEMPTが多いほど値が大きくなる。逆に、eFG%・2PTS%・3PTS%・ASTが多いほど値が小さくなるといった特徴があるようです。要は、アシストが多く、効率良くシュートを打てているかを示していそうです。
- 最もこのスコアが小さかったセルビアが、一番チームプレーで効率的なシュートを打てていたのかもしれません。 -embedded_2|3PTS_ATTEMTが多いほど値が大きくなる。逆に、FT_ATTEMPT・FTR・DREB・BLKが多いほど値が小さくなる傾向があるようです。解釈が分かれる所ではありますが、インサイドへのアタックが多いチームや、ディフェンスの際に中を固めているチームほど値が小さくなるようです。
- 最もこの値が小さかったアメリカはインサイドへのアタックを果敢に仕掛けていたり、速攻を繰り出そうとしていたはずなので、結果的にFT獲得数の面で一歩抜きん出ていたのかもしれません(FT_ATTEMPT|大会2位、FTR|大会3位)。また、身体能力も高いためか、ブロック数やDREBも多かったです(BLK|大会1位、DREB|大会1位)。
- インサイドの層が薄い印象でしたので、ブロック数とDREBに関しては少し意外な結果でした。※OREB|大会21位、OREB%大会16位なので、アメリカがインサイドのチームではないという感覚は間違ってなさそうです。
t-SNE
次に、t-SNEでの結果を見ていきます。
summary_embedding(
summary_team_df=summary_team_df,
model_name="tSNE",
N=2,
label_col="TEAM_LABEL",
size_col="RANK",
feature_cols=feature_cols
)
次元削減空間の可視化
 なんとなく上に上位チーム、下に下位チームが来る結果となりました。
なんとなく上に上位チーム、下に下位チームが来る結果となりました。
日本は主成分分析(PCA)同様にドイツ・ブラジル・フィンランド、更にスロベニアが近いチームとなっています。また、やはりアメリカとラトビア、更にはアンゴラは少し外れた位置におり、特徴的なチームだったように見えます。
次元削減結果のスコアの可視化
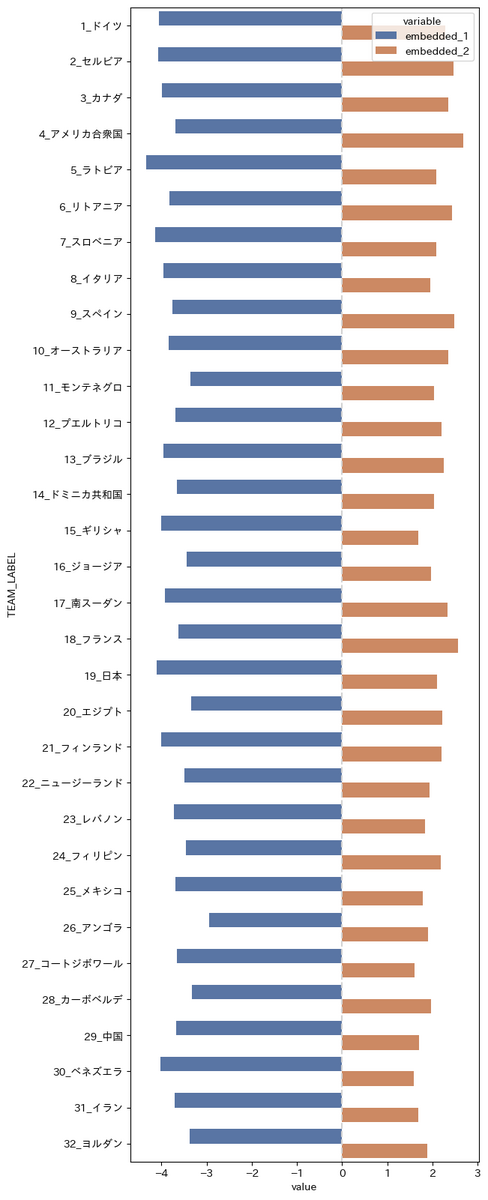 t-SNEの場合は棒グラフで可視化してもぱっとは何を言えるかは分からなさそうです。
t-SNEの場合は棒グラフで可視化してもぱっとは何を言えるかは分からなさそうです。
スコアと特徴量の可視化
スコアと各スタッツ(特徴量)の相関係数と、散布図を見ていきます。
embedded_1


embedded_1については、2PTS_ATTEMPTやOREBが高いと値が高く、eFG%や3PTS%・ASTが低いと値が(比較的)低くなっていたようです。インサイド偏重なチームだとこのembedded_1が顕著に高く出ていたようです。
embedded_2


embedded_2については、DREBやBLK、eFG%や2PTS%が高いと値が高くなっていたようです。主成分分析同様、アメリカが一番上に位置づいているのも納得ですね。
UMAP
次に、UMAPでの結果を見ていきます。
summary_embedding(
summary_team_df=summary_team_df,
model_name="UMAP",
N=2,
label_col="TEAM_LABEL",
size_col="RANK",
feature_cols=feature_cols
)
次元削減空間の可視化
 UMAPだと左上側に上位チーム、右下側に下位チームが位置づきました。やはり、日本に近いチームとしてはブラジル・フィンランドが位置しています。
UMAPだと左上側に上位チーム、右下側に下位チームが位置づきました。やはり、日本に近いチームとしてはブラジル・フィンランドが位置しています。
次元削減結果のスコアの可視化
 UMAPもt-SNE同様、棒グラフとして可視化しても、ぱっとは特徴は分からなさそうです。
UMAPもt-SNE同様、棒グラフとして可視化しても、ぱっとは特徴は分からなさそうです。
スコアと特徴量の可視化
スコアと各スタッツ(特徴量)の相関係数と、散布図を見ていきます。
embedded_1


embedded_1については、ASTやeFG%、2PTS%が高いと値が低くなり、TO・TO%が多いと値が高くなっているようです。ミスが多いチームほど値が高くなっている→下位チームがプロットされているというのはある種納得の行く結果のように思えます。
embedded_2


embedded_2については、eFG%・2PTS%・3PTS%やASTが高いほど値が高くなっているので、効率的にシュートを打てているかどうかを表していそうです。上位のヨーロッパやアメリカのチームがプロットされているのもよくわかります。
主成分分析(PCA)+UMAP
最後に、主成分分析(PCA)+UMAPでの結果を見ていきます。これは、UMAPを行う前にPCAを行ったほうがより良い結果が得られることがあるらしいとのことで試してみました。
まずは、PCAでどのくらいまで次元削減しておくべきか、累積寄与率を見て確認しておきます。
# PCAの累積寄与率を確認 pca = PCA(n_components=15, random_state=0) X_embedded = pca.fit_transform(summary_team_df[feature_cols]) plt.plot(np.cumsum(pca.explained_variance_ratio_), '-o') plt.xlabel("principal components(PC1, PC2, ..,)") plt.ylabel("cumulative contribution rate") plt.grid() plt.show()
 10個もあればほぼ寄与率100%なので、PCAのn_componentsは10にしておきます。
10個もあればほぼ寄与率100%なので、PCAのn_componentsは10にしておきます。
summary_embedding_pca_umap(
summary_team_df=summary_team_df,
model_name="PCA_UMAP",
pca_N=10,
umap_N=2,
label_col="TEAM_LABEL",
size_col="RANK",
feature_cols=feature_cols
)
次元削減空間の可視化
 先程のUMAPと同様、左上に上位チーム、右下に下位チームがプロットされていそうです。ただし、今回はアメリカやラトビアが他の時ほど目立っている形ではなくなりました。また、日本に似ているチームとして、ブラジル・フィンランドの他にフランスも入ってきそうです。
先程のUMAPと同様、左上に上位チーム、右下に下位チームがプロットされていそうです。ただし、今回はアメリカやラトビアが他の時ほど目立っている形ではなくなりました。また、日本に似ているチームとして、ブラジル・フィンランドの他にフランスも入ってきそうです。
次元削減結果のスコアの可視化
 なんとなくではありますが、上位チームやヨーロッパ系、日本はembedded_1がマイナスとなっており、他の下位チームやアジア・アフリカ系のチームはプラスになっているように見受けられます。
なんとなくではありますが、上位チームやヨーロッパ系、日本はembedded_1がマイナスとなっており、他の下位チームやアジア・アフリカ系のチームはプラスになっているように見受けられます。
スコアと特徴量の可視化
スコアと各スタッツ(特徴量)の相関係数と、散布図を見ていきます。
embedded_1


今回もASTやeFG%・2PTS%・3PTS%が高いほどembedded_1が低くなっているため、これは効率よくシュートを打てているかを表していそうです。
embedded_2

 TOやTO%が多いと値が低くなっているため、ミスの多さを示す指標となっているようです。
TOやTO%が多いと値が低くなっているため、ミスの多さを示す指標となっているようです。
まとめ
様々な次元削減の方法を試しながら、各チームの特徴をマッピングしてみました。やはり上位チームは効率的なシュートを打てているということが改めてよくわかりました。また、日本は下位チームに位置していながらも上位チームのブラジルや、ヨーロッパのチームのフィンランドに似た傾向を取っており、確実に世界と戦うための戦い方を身につけつつあることが、今回の分析からも見て取れたように思えます。
次回は、今回の次元削減とは逆の考え方(スタッツをどうまとめるかではなく、スタッツがどの因子から生まれているか)を用いた、因子分析で今回と同様の分析を行っていきます。
参考にさせていただいた記事
FIBA Basketball World Cup 2023をデータ分析してみた(Part.3|LightGBM+SHAP分析)
本記事は、全5回に分けてFIBAバスケットボールワールドカップ2023の全92試合を分析してみたシリーズ第3回目です。
- 相関分析・可視化分析|勝敗と相関が高いスタッツの項目は何か?勝利したチームと敗北したチームのスタッツの差はどう違うのか?
- 決定木分析|勝利するチームのスタッツの条件は?(その1)
- LightGBM+SHAP分析|勝利するチームのスタッツの条件は?(その2)
- 次元削減分析(主成分分析・t-SNE・UMAP)|スタッツから見る大会参加チームの特徴は?(その1)
- 因子分析+クラスタリング|スタッツから見る大会参加チームの特徴は?(その2)
前回は、決定木分析を行い、勝利する際のスタッツの条件分岐点を探ってみました。 bballdatanote.hatenablog.com
今回はLightGBMでスタッツから勝敗を予測するMLモデルを作り、さらにSHAPというMLモデルを解釈するための手法で分析を行っていきます。決定木よりもより高精度に勝敗を予測できる(はずの)MLモデルを使うことで、改めて違う観点から勝利する際のスタッツの条件分岐点を探っていきます。
目次は次の通りです。
データの準備・前処理
前回同様、大会公式サイトのデータを用いて、以下のように試合別・チーム別のデータに集約していきます。また、追加スタッツとしてFour FactorsとField Goal Percentageも出しておきます。
team_df.head()
| GAME_KEY | TEAM | GAME_POSITION | RESULT | OREB | DREB | REB | AST | PF | TO | ST | BLK | FG_MADE | FG_ATTEMPT | 2PTS_MADE | 2PTS_ATTEMPT | 3PTS_MADE | 3PTS_ATTEMPT | FT_MADE | FT_ATTEMPT | eFG% | TO% | FTR | DREB_OPPOSITE | OREB% | 2PTS% | 3PTS% | FT% | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 試合日1_ドイツ_日本 | 日本 | right | LOSE | 6 | 24 | 30 | 17 | 16 | 12 | 5 | 3 | 23 | 65 | 17 | 30 | 6 | 35 | 11 | 17 | 0.400000 | 0.142045 | 0.261538 | 36 | 0.142857 | 0.566667 | 0.171429 | 0.647059 |
| 1 | 試合日1_南スーダン_プエルトリコ | 南スーダン | left | LOSE | 8 | 27 | 35 | 23 | 23 | 19 | 9 | 5 | 34 | 67 | 24 | 41 | 10 | 26 | 18 | 24 | 0.582090 | 0.196769 | 0.358209 | 26 | 0.235294 | 0.585366 | 0.384615 | 0.750000 |
| 2 | 試合日1_スペイン_コートジボワール | スペイン | left | WIN | 14 | 28 | 42 | 29 | 14 | 17 | 7 | 5 | 34 | 64 | 23 | 35 | 11 | 29 | 15 | 22 | 0.617188 | 0.187472 | 0.343750 | 16 | 0.466667 | 0.657143 | 0.379310 | 0.681818 |
| 3 | 試合日2_オーストラリア_ドイツ | ドイツ | right | WIN | 5 | 20 | 25 | 18 | 19 | 12 | 9 | 3 | 31 | 61 | 20 | 31 | 11 | 30 | 12 | 15 | 0.598361 | 0.150754 | 0.245902 | 22 | 0.185185 | 0.645161 | 0.366667 | 0.800000 |
| 4 | 試合日2_レバノン_カナダ | レバノン | left | LOSE | 6 | 10 | 16 | 19 | 18 | 22 | 12 | 1 | 30 | 62 | 22 | 43 | 8 | 19 | 5 | 5 | 0.548387 | 0.255220 | 0.080645 | 24 | 0.200000 | 0.511628 | 0.421053 | 1.000000 |
LightGBM+SHAP分析
それでは分析をしていきます。いつも通り、勝敗(RESULT)がそのままではWINとLOSEで相関係数を計算できないので、WINの場合は1、LOSEの場合は0としておきます。
df = team_df.clone().with_columns(
RESULT_INT = pl.col("RESULT").map_dict({"WIN": 1, "LOSE": 0})
)
次に、勝敗と比較するスタッツを前回同様に指定しておきます。
feature_cols = [
'OREB', # オフェンスリバウンド
'DREB', # ディフェンスリバウンド
'AST', # アシスト
'PF', # ファール
'TO', # ターンオーバー
'ST', # スティール
'BLK', # ブロック
'2PTS_ATTEMPT', # 2ポイントの試投数
'3PTS_ATTEMPT', # 3ポイントの試投数
'FT_ATTEMPT', # フリースローの試投数
'eFG%', # efficient Field Goal Percentage(Four Factors)
'TO%', # Turn Over Percentage (Four Factors)
'FTR', # Free Throw Rate (Four Factors)
'OREB%', # Offensive Rebound Percentage (Four Factors)
'2PTS%', # 2ポイント成功率
'3PTS%', # 3ポイント成功率
'FT%', # フリースロー成功率
]
汎化性能の評価
LightGBM自体の汎化性能を見るために、TrainデータとTestデータに分けておきます。試合(GAME_KEY)レベルでTrainかTestに分けたいので、通常利用するtrain_test_splitではなく、GroupShuffleSplitを利用します。
from sklearn.model_selection import GroupShuffleSplit # Train/Testに分ける df = df.to_pandas() splitter = GroupShuffleSplit(test_size=0.3, random_state=0) split = splitter.split(df, groups=df["GAME_KEY"]) train_inds, test_inds = next(split) train_df = df.iloc[train_inds] test_df = df.iloc[test_inds] # 特徴量Xと目的変数yに分ける train_X = train_df[feature_cols] train_y = train_df["RESULT_INT"] test_X = test_df[feature_cols] test_y = test_df["RESULT_INT"]
次に、LightGBMを学習させ、汎化性能を見ておきます。どれくらいの確率で勝敗を予測できるMLモデルなのかを確認するためです。一般的には、決定木(DecisionTree)よりもLightGBMの方がより優れた性能を発揮することが多いです。
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, roc_auc_score, confusion_matrix import lightgbm as lgb from lightgbm import LGBMClassifier # 2値分類のモデルの評価用関数 def show_binary_classification_score(cls, x, y): pred = cls.predict(x) pred_prob = cls.predict_proba(x)[:, 1] # 各種精度指標を計算 acc = accuracy_score(y, pred) precision = precision_score(y, pred) recall = recall_score(y, pred) f1 = f1_score(y, pred) auc = roc_auc_score(y, pred) conf_mat = confusion_matrix(y, pred) conf_mat = pd.DataFrame(conf_mat, index=["LOSE", "WIN"], columns=["LOSE", "WIN"]) # 各種精度指標を表示 print(f"Accuracy:\t{acc}") print(f"Precision:\t{precision}") print(f"Recall:\t{recall}") print(f"F1:\t{f1}") print(f"AUC:\t{auc}") print(f"混同行列:\n{conf_mat}") # Trainデータで学習 lgb_model = LGBMClassifier(verbose=-1, random_state=0) lgb_model = lgb_model.fit(train_X, train_y) # Testデータで評価 show_binary_classification_score(lgb_model, test_X, test_y)
Accuracy: 0.8392857142857143
Precision: 0.8275862068965517
Recall: 0.8571428571428571
F1: 0.8421052631578947
AUC: 0.8392857142857143
混同行列:
LOSE WIN
LOSE 23 5
WIN 4 24
前回の決定木ではAccuracyが約0.73、F1も約0.75だったので、およそ10%程度精度が高いMLモデルとなっていそうです。 それでは、SHAPにかける前の事前情報として、LightGBMの特徴量重要度(Feature Importance)を見ていきます。どのスタッツが予測にどの程度寄与しているかを示すものです。
lgb.plot_importance(lgb_model, figsize=(15,10), importance_type='gain')

前回同様、DREBとeFG%が重要であるという結果が見て取れますね。
SHAPによる分析
それでは、さっそくSHAPによる分析を行っていきましょう。 前回同様、全てのデータを使って分析していきます。
まずは、各スタッツがどの程度勝敗に寄与していたかというshap値(shap_values)を求めておきます。
import shap shap.initjs() explainer = shap.TreeExplainer(lgb_model) X = df[feature_cols] y = df["RESULT_INT"] shap_values = explainer.shap_values(X=X)
次に、各スタッツの指標とshap値の関係性を可視化していきます。※他にも色んな可視化の方法がありますが、今回の目的からは外れるため、スキップします。
概観
まずは全体を概観しましょう。
n_rows = 5 n_cols = 4 fig, axes = plt.subplots(nrows=n_rows, ncols=n_cols, figsize=(20, 20), tight_layout=True) for idx, col in enumerate(feature_cols): i = idx // n_cols j = idx % n_cols shap.dependence_plot(ind=col, shap_values=shap_values[1], features=X, feature_names=feature_cols, ax=axes[i, j], show=False) axes[i, j].axhline(0, color="gray", linestyle="--") plt.show()

それぞれのグラフの横軸がスタッツそのものの値、縦軸がshap値です。shap値が大きいほど、勝利に寄与しているという読み方となります。また、shap値が0のラインである点線よりも上の場合は勝利に対してプラスの方向に寄与していることを示します。 それぞれの点で赤や青の色がついていますが、今回は簡単のため、一旦無視して分析を進めます。
なお、全てのグラフがとても興味深い結果を示していますが、今回もいくつか気になるものをピックアップして分析していこうと思います。
ディフェンスリバウンド
まずは特徴量重要度でも高い値を示していた、DREBについてです。23本あたりを境に、明確に勝利にプラスに働いているか、マイナスに働いているかが分かれています。ただし、30本を超えてくるとshap値も横ばいとなっているため、これは単純に試合のペースが早くなってリバウンドの総数が増えただけで、ディフェンスでシュートを落とさせたということではないことを示しているかもしれません。

eFG%
次に、2番目に高い特徴量重要度を示していた、eFG%についてです。決定木分析でも58.4%を境に勝敗が別れていましたが、今回の分析でもその値付近でshap値が0を超えるかどうかが決まっています。また、50%から70%くらいまではeFG%が高いほどshap値も高くなる傾向であることが見て取れます。
逆に言うと、それ以下、あるいはそれ以上となるともはや勝敗への影響は(eFG%というスタッツだけで見ると)一定ということなのかもしれません。

スティール
他でshap値がある程度大きい所ではST(スティール)が挙げられます。こちらは10本を超えてくると(DEFがそれだけ厳しいと)勝利に対してプラスの影響が一気に出てくるようです。

3ポイント成功率
また、興味深いグラフだなと感じたのは、3PTS%(スリーポイントの成功率)です。日本代表監督であるトム・ホーバス氏は、女子代表を率いた東京オリンピックの際も、男子代表を率いた今大会の際も40%を目指すということを掲げていました。 実際にshap値で見てみると40%位を境に、一貫してshap値はプラスの値を取るように(勝利に寄与するように)なっています。30%を超えてもプラスになっているケースは見受けられますが、一貫してプラスになるという面ではやはり40%というのが目標とすべき値のようです。

まとめ
今回は、LightGBMとSHAPを用いた分析で、勝敗チーム間のスタッツの違いを見てきました。決定木よりも更に高精度に勝敗を予測できるMLモデルを利用した場合に、どのようなスタッツが勝利に寄与しているのかを概観することが出来ました。
また、どこまでの値を目標とすればよいのかについても一定の示唆が得られる分析結果だったかと思います。個人的にはトム・ホーバス氏が掲げるスリーポイントの成功率40%の正当性が確認できた部分が非常に興味深かったです。
次回以降は、次元圧縮分析・因子分析を利用して、各チームの特徴をマッピングし、どんなチームが似ていると判断できるのか、考察していこうと思います。
FIBA Basketball World Cup 2023をデータ分析してみた(Part.2|決定木分析)
本記事は、全5回に分けてFIBAバスケットボールワールドカップ2023の全92試合を分析してみたシリーズ第2回目です。
- 相関分析・可視化分析|勝敗と相関が高いスタッツの項目は何か?勝利したチームと敗北したチームのスタッツの差はどう違うのか?
- 決定木分析|勝利するチームのスタッツの条件は?(その1)
- LightGBM+SHAP分析|勝利するチームのスタッツの条件は?(その2)
- 次元削減分析(主成分分析・t-SNE・UMAP)|スタッツから見る大会参加チームの特徴は?(その1)
- 因子分析+クラスタリング|スタッツから見る大会参加チームの特徴は?(その2)
前回は、シンプルな相関分析と可視化分析を行いました bballdatanote.hatenablog.com
今回は決定木分析を行い、勝利する際のスタッツの条件分岐点を探っていきます。
目次は次の通りです。
データの準備・前処理
前回同様、大会公式サイトのデータを用いて、以下のように試合別・チーム別のデータに集約していきます。また、追加スタッツとしてFour FactorsとField Goal Percentageも出しておきます。
team_df.head()
| GAME_KEY | TEAM | GAME_POSITION | RESULT | OREB | DREB | REB | AST | PF | TO | ST | BLK | FG_MADE | FG_ATTEMPT | 2PTS_MADE | 2PTS_ATTEMPT | 3PTS_MADE | 3PTS_ATTEMPT | FT_MADE | FT_ATTEMPT | eFG% | TO% | FTR | DREB_OPPOSITE | OREB% | 2PTS% | 3PTS% | FT% | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 試合日1_ドイツ_日本 | 日本 | right | LOSE | 6 | 24 | 30 | 17 | 16 | 12 | 5 | 3 | 23 | 65 | 17 | 30 | 6 | 35 | 11 | 17 | 0.400000 | 0.142045 | 0.261538 | 36 | 0.142857 | 0.566667 | 0.171429 | 0.647059 |
| 1 | 試合日1_南スーダン_プエルトリコ | 南スーダン | left | LOSE | 8 | 27 | 35 | 23 | 23 | 19 | 9 | 5 | 34 | 67 | 24 | 41 | 10 | 26 | 18 | 24 | 0.582090 | 0.196769 | 0.358209 | 26 | 0.235294 | 0.585366 | 0.384615 | 0.750000 |
| 2 | 試合日1_スペイン_コートジボワール | スペイン | left | WIN | 14 | 28 | 42 | 29 | 14 | 17 | 7 | 5 | 34 | 64 | 23 | 35 | 11 | 29 | 15 | 22 | 0.617188 | 0.187472 | 0.343750 | 16 | 0.466667 | 0.657143 | 0.379310 | 0.681818 |
| 3 | 試合日2_オーストラリア_ドイツ | ドイツ | right | WIN | 5 | 20 | 25 | 18 | 19 | 12 | 9 | 3 | 31 | 61 | 20 | 31 | 11 | 30 | 12 | 15 | 0.598361 | 0.150754 | 0.245902 | 22 | 0.185185 | 0.645161 | 0.366667 | 0.800000 |
| 4 | 試合日2_レバノン_カナダ | レバノン | left | LOSE | 6 | 10 | 16 | 19 | 18 | 22 | 12 | 1 | 30 | 62 | 22 | 43 | 8 | 19 | 5 | 5 | 0.548387 | 0.255220 | 0.080645 | 24 | 0.200000 | 0.511628 | 0.421053 | 1.000000 |
決定木分析
それでは決定木分析をしていきます。勝敗(RESULT)がそのままではWINとLOSEで相関係数を計算できないので、WINの場合は1、LOSEの場合は0としておきます。
df = team_df.clone().with_columns(
RESULT_INT = pl.col("RESULT").map_dict({"WIN": 1, "LOSE": 0})
)
次に、勝敗と比較するスタッツを前回同様に指定しておきます。
feature_cols = [
'OREB', # オフェンスリバウンド
'DREB', # ディフェンスリバウンド
'AST', # アシスト
'PF', # ファール
'TO', # ターンオーバー
'ST', # スティール
'BLK', # ブロック
'2PTS_ATTEMPT', # 2ポイントの試投数
'3PTS_ATTEMPT', # 3ポイントの試投数
'FT_ATTEMPT', # フリースローの試投数
'eFG%', # efficient Field Goal Percentage(Four Factors)
'TO%', # Turn Over Percentage (Four Factors)
'FTR', # Free Throw Rate (Four Factors)
'OREB%', # Offensive Rebound Percentage (Four Factors)
'2PTS%', # 2ポイント成功率
'3PTS%', # 3ポイント成功率
'FT%', # フリースロー成功率
]
汎化性能の評価
決定木自体の汎化性能を見るために、TrainデータとTestデータに分けておきます。試合(GAME_KEY)レベルでTrainかTestに分けたいので、通常利用するtrain_test_splitではなく、GroupShuffleSplitを利用します。
from sklearn.model_selection import GroupShuffleSplit # Train/Testに分ける df = df.to_pandas() splitter = GroupShuffleSplit(test_size=0.3, random_state=0) split = splitter.split(df, groups=df["GAME_KEY"]) train_inds, test_inds = next(split) train_df = df.iloc[train_inds] test_df = df.iloc[test_inds] # 特徴量Xと目的変数yに分ける train_X = train_df[feature_cols] train_y = train_df["RESULT_INT"] test_X = test_df[feature_cols] test_y = test_df["RESULT_INT"]
次に、決定木を学習させ、汎化性能を見ておきます。どれくらいの確率で勝敗を分類できる決定木なのかを確認するためです。
可視化の際に、あまり決定木が深すぎても解釈しきれないので、決定木の深さを示すパラメータであるmax_depthは5にしておきます。
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, roc_auc_score, confusion_matrix from sklearn.tree import DecisionTreeClassifier # 2値分類のモデルの評価用関数 def show_binary_classification_score(cls, x, y): pred = cls.predict(x) pred_prob = cls.predict_proba(x)[:, 1] # 各種精度指標を計算 acc = accuracy_score(y, pred) precision = precision_score(y, pred) recall = recall_score(y, pred) f1 = f1_score(y, pred) auc = roc_auc_score(y, pred) conf_mat = confusion_matrix(y, pred) conf_mat = pd.DataFrame(conf_mat, index=["LOSE", "WIN"], columns=["LOSE", "WIN"]) # 各種精度指標を表示 print(f"Accuracy:\t{acc}") print(f"Precision:\t{precision}") print(f"Recall:\t{recall}") print(f"F1:\t{f1}") print(f"AUC:\t{auc}") print(f"混同行列:\n{conf_mat}") # Trainデータで学習 dt = DecisionTreeClassifier(max_depth=5, random_state=0) dt = dt.fit(train_X, train_y) # Testデータで評価 show_binary_classification_score(dt, test_X, test_y)
# 出力
Accuracy: 0.7321428571428571
Precision: 0.7096774193548387
Recall: 0.7857142857142857
F1: 0.7457627118644068
AUC: 0.7321428571428572
混同行列:
LOSE WIN
LOSE 19 9
WIN 6 22
ここでは各指標の詳細な説明は避けますが、概ね7割強程度の精度で正確に分類できていそうです。
決定木の可視化
それでは、実際に決定木を可視化していきます。可視化する際には、Train/Testの全てのデータを使っていきます。
可視化にあたっては、sklearnのplot_treeもよく使われていますが、今回はより綺麗に可視化ができるdtreevizを使っていきます。
import dtreeviz # 学習 X = df[feature_cols] y = df["RESULT_INT"] dt.fit(X, y) # 可視化 viz_model = dtreeviz.model( dt, X, y, target_name="RESULT_INT", feature_names=feature_cols, class_names=["LOSE", "WIN"] ) v = viz_model.view() # render as SVG into internal object v

eFG%が58.4%以上かどうかで最初の分岐が入っています。58.4%以下の場合、DREBが24.5本以下になると一気にLOSE、敗北の割合が高くなっていることがわかります。 逆にeFG%が58.4%を上回っている場合、DREBが20.5本よりも多く取れていたらほぼほぼ勝利、さらに3PTS_ATTEMPTが20を上回ったチームは全チーム勝利していることがわかります。
前回の相関分析・可視化分析でも見て取れましたが、効率的にシュートを成功させることができ、DREBをしっかり抑えて相手のオフェンス回数を減らすことが重要であると言えそうです。
番外編|Four Factorsだけで見た場合どうなるか?
先程はできる限りのスタッツ情報を含めて分析しましたが、今度はFour Factorsだけで見た場合どうなるのかを試してみます。今回は4種類のスタッツしか含めないので、max_depthは3にしておきます。
汎化性能の確認
# Xとyに分ける FOUR_FACTORS_COLS = [ "eFG%", # effecient Field Goal% "OREB%", # Offensive Rebound% "FTR", # Free Throw Rate "TO%" # Turn Over% ] train_X = train_df[FOUR_FACTORS_COLS] train_y = train_df["RESULT_INT"] test_X = test_df[FOUR_FACTORS_COLS] test_y = test_df["RESULT_INT"] # 学習 dt = DecisionTreeClassifier(max_depth=3,random_state=0) dt = dt.fit(train_X, train_y) # 評価 show_binary_classification_score(dt, test_X, test_y)
Accuracy: 0.7142857142857143
Precision: 0.6764705882352942
Recall: 0.8214285714285714
F1: 0.7419354838709677
AUC: 0.7142857142857143
混同行列:
LOSE WIN
LOSE 17 11
WIN 5 23
Four Factorsだけで学習しても、7割強の精度で分類できていそうです。Recallに至っては8割強と、指標によってはスタッツを絞る前よりも良くなっています。
決定木の可視化
それでは決定木を可視化していきます。
X = df[FOUR_FACTORS_COLS] y = df["RESULT_INT"] dt.fit(X, y) viz_model = dtreeviz.model( dt, X, y, target_name="RESULT_INT", feature_names=FOUR_FACTORS_COLS, class_names=["LOSE", "WIN"] ) v = viz_model.view() # render as SVG into internal object v

やはり、eFG%は58.4%というのが最初の条件になってきています。また、Four Factorsだけで判断する場合はeFG%とOREB%でほぼほぼ勝敗を分類出来てしまっているようです。逆に、FTRが出てこないのは少し意外な結果でした。
もちろん、これは他のスタッツを考慮しない場合の結果ですし、あくまでFIBAバスケットボールワールドカップ2023という大会だけを見た場合なので、必ずしもFTRが重要ではないとは言い切れないことには注意が必要です。
まとめ
今回は、機械学習アルゴリズムである決定木を用いた分析で、勝敗チーム間のスタッツの違いを見てきました。シュートを効率よく決める(eFG% > 58.4%)・リバウンドを制する(DREB > 20.5)といったごく当たり前のことを出来たチームが勝っているということを、更に具体的な定量指標で見ることが出来ました。
FIBA Basketball World Cup 2023をデータ分析してみた(Part.1|相関分析・可視化分析)
日本男子代表がアジア1位になり、パリ五輪出場権を獲得したFIBAバスケットボールワールドカップ2023。代表の活躍に胸を踊らせている中、次のツイートに触発され、自分も全92試合についてデータ分析してみたのでその備忘です。
📊バスケW杯日本代表アドバンスドスタッツ
— 柳鳥 亮@データスタジアム (@ds_yanadori) 2023年9月5日
eFG%: 52.0%
相手eFG%: 51.3%
視界がにじみます。ついに日本がeFG%で相手を上回る時代が!五輪では約10%下回っていました。
昨季B1でCS進出8チーム中7チームがeFG%で相手を上回っていました。強者の数字!@chrisnewtokyoさん、後押しありがとうございます! https://t.co/xYEfO6qXE6
私の場合は日本にフォーカスするのではなく、全チームを比較した場合に、強いチームはどんなスタッツを残していたのかについて分析してみました。色々と分析してみたら長くなったので、全5回に分けていきます。 今回は第1回目です。
- 相関分析・可視化分析|勝敗と相関が高いスタッツの項目は何か?勝利したチームと敗北したチームのスタッツの差はどう違うのか?
- 決定木分析|勝利するチームのスタッツの条件は?(その1)
- LightGBM+SHAP分析|勝利するチームのスタッツの条件は?(その2)
- 次元削減分析(主成分分析・t-SNE・UMAP)|スタッツから見る大会参加チームの特徴は?(その1)
- 因子分析|スタッツから見る大会参加チームの特徴は?(その2)
目次は次の通りです。
データの準備
まずは、各チームのスタッツを大会公式サイトから取得してきます。取得する際には、以下の記事でまとめたスクレイピング方法を使いました。なお、公式サイトの規約上、データの複製・頒布及びそれに準じる行為は認められていないようなので、ソースコード及び取得データ自体の公開は控えておきます。
取得した結果は、以下のようなものとなります。どの試合で、各チームのどの選手がどんなスタッツを残したのかというデータです。なお、今後分析がしやすいように、GAME_POSITION(試合表示が左側のチームなのか右側のチームなのか)やRESULT(WINかLOSE)などをフラグ立てしています。
| PHASE | GAME_KEY | TEAM | GAME_POSITION | RESULT | PLAYERS_NUMBER | PLAYERS | PTS | OREB | DREB | REB | AST | PF | TO | ST | BLK | P_M | EFF | FG_MADE | FG_ATTEMPT | 2PTS_MADE | 2PTS_ATTEMPT | 3PTS_MADE | 3PTS_ATTEMPT | FT_MADE | FT_ATTEMPT | PLAY_TIME | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | FirstRoundグループA | 試合日1_アンゴラ_イタリア | アンゴラ | left | LOSE | 0 | Eduardo Francisco | 3.0 | 2.0 | 3.0 | 5.0 | 0.0 | 4.0 | 0.0 | 0.0 | 0.0 | 6.0 | 4.0 | 1.0 | 4.0 | 1.0 | 4.0 | 0.0 | 0.0 | 1.0 | 2.0 | 1002 |
| 1 | FirstRoundグループA | 試合日1_アンゴラ_イタリア | アンゴラ | left | LOSE | 1 | Gerson Domingos | 4.0 | 0.0 | 2.0 | 2.0 | 3.0 | 0.0 | 1.0 | 1.0 | 0.0 | -10.0 | 2.0 | 1.0 | 8.0 | 1.0 | 2.0 | 0.0 | 6.0 | 2.0 | 2.0 | 1098 |
| 2 | FirstRoundグループA | 試合日1_アンゴラ_イタリア | アンゴラ | left | LOSE | 2 | Dimitri Maconda | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 3.0 | 0.0 | 0.0 | -11.0 | -3.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 443 |
| 3 | FirstRoundグループA | 試合日1_アンゴラ_イタリア | アンゴラ | left | LOSE | 3 | Gerson Goncalves | 7.0 | 0.0 | 3.0 | 3.0 | 4.0 | 2.0 | 0.0 | 0.0 | 0.0 | 7.0 | 5.0 | 3.0 | 12.0 | 3.0 | 6.0 | 0.0 | 6.0 | 1.0 | 1.0 | 1709 |
| 4 | FirstRoundグループA | 試合日1_アンゴラ_イタリア | アンゴラ | left | LOSE | 5 | Childe Dundao | 19.0 | 1.0 | 2.0 | 3.0 | 3.0 | 2.0 | 3.0 | 2.0 | 0.0 | -12.0 | 17.0 | 6.0 | 12.0 | 2.0 | 4.0 | 4.0 | 8.0 | 3.0 | 4.0 | 1766 |
データの前処理
それでは、早速分析のための前処理から行っていきます。まずは必要なライブラリをインポートし、データを読み込みます。
# データハンドリング系 import polars as pl import numpy as np import pandas as pd # 可視化系 import matplotlib.pyplot as plt import seaborn as sns import japanize_matplotlib %matplotlib inline # その他諸々 from pathlib import Path from tqdm.notebook import tqdm import warnings warnings.filterwarnings("ignore")
df = pl.read_csv("[ファイル名].csv")
読み込んだデータは上記に掲載しているものです。 今は試合別・チーム別・選手別のデータになっているので、これをチーム間の勝敗比較ができるように、試合別・チーム別のデータに集約していきます。また、追加スタッツとしてFour FactorsとField Goal Percentageも出しておきます。
前処理用の関数(ここをクリックすると表示されます)
def process_team_stats(df, key_cols=["GAME_KEY", "TEAM", "GAME_POSITION", "RESULT"]): tmp_df = df.clone() tmp_df = _groupby_team_stats(tmp_df, key_cols) tmp_df = _calc_eFG_percentage(tmp_df) tmp_df = _calc_TO_percentage(tmp_df) tmp_df = _calc_FT_rate(tmp_df) tmp_df = _calc_OREB_percentage(tmp_df) tmp_df = _calc_FG_percentage(tmp_df) return tmp_df def _groupby_team_stats(df, key_cols): numeric_cols = [col for col in df.columns if df[col].is_numeric()] remove_cols = [col for col in df.columns if col in IGNORE_NUMERICAL_COLS] team_df = df.clone().group_by( key_cols ).agg( pl.sum(numeric_cols) ) team_df = team_df.drop(remove_cols) return team_df def _calc_eFG_percentage(df): tmp_df = df.clone() tmp_df = tmp_df.with_columns( ((pl.col("FG_MADE") + 0.5*pl.col("3PTS_MADE")) / pl.col("FG_ATTEMPT")).alias("eFG%") ) return tmp_df def _calc_TO_percentage(df): tmp_df = df.clone() tmp_df = tmp_df.with_columns( (pl.col("TO") / (pl.col("FG_ATTEMPT") + 0.44*pl.col("FT_ATTEMPT") + pl.col("TO"))).alias("TO%") ) return tmp_df def _calc_FT_rate(df): tmp_df = df.clone() tmp_df = tmp_df.with_columns( FTR = pl.col("FT_ATTEMPT") / pl.col("FG_ATTEMPT") ) return tmp_df def _calc_OREB_percentage(df): tmp_df = df.clone() if not "DREB_OPPOSITE" in tmp_df.columns: tmp_df = tmp_df.with_columns( OPPOSITE = pl.col("GAME_POSITION").map_dict({ "left": "right", "right": "left" }) ) opposite_df = tmp_df[["GAME_KEY", "GAME_POSITION", "DREB"]].clone().with_columns( pl.col("DREB").alias("DREB_OPPOSITE") ).drop("DREB") tmp_df = tmp_df.join( opposite_df, left_on=["GAME_KEY", "OPPOSITE"], right_on=["GAME_KEY", "GAME_POSITION"], how="left" ) tmp_df = tmp_df.with_columns( (pl.col("OREB") / (pl.col("OREB") + pl.col("DREB_OPPOSITE"))).alias("OREB%") ) if "OPPOSITE" in tmp_df.columns: tmp_df = tmp_df.drop("OPPOSITE") return tmp_df def _calc_FG_percentage(df): tmp_df = df.clone() for fg in ["2PTS", "3PTS", "FT"]: tmp_df = tmp_df.with_columns( (pl.col(f"{fg}_MADE") / pl.col(f"{fg}_ATTEMPT")).alias(f"{fg}%") ) return tmp_df
team_df = process_team_stats(df)
前処理した結果、次のようなデータになっています。
| GAME_KEY | TEAM | GAME_POSITION | RESULT | OREB | DREB | REB | AST | PF | TO | ST | BLK | FG_MADE | FG_ATTEMPT | 2PTS_MADE | 2PTS_ATTEMPT | 3PTS_MADE | 3PTS_ATTEMPT | FT_MADE | FT_ATTEMPT | eFG% | TO% | FTR | DREB_OPPOSITE | OREB% | 2PTS% | 3PTS% | FT% | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 試合日1_ドイツ_日本 | 日本 | right | LOSE | 6 | 24 | 30 | 17 | 16 | 12 | 5 | 3 | 23 | 65 | 17 | 30 | 6 | 35 | 11 | 17 | 0.400000 | 0.142045 | 0.261538 | 36 | 0.142857 | 0.566667 | 0.171429 | 0.647059 |
| 1 | 試合日1_南スーダン_プエルトリコ | 南スーダン | left | LOSE | 8 | 27 | 35 | 23 | 23 | 19 | 9 | 5 | 34 | 67 | 24 | 41 | 10 | 26 | 18 | 24 | 0.582090 | 0.196769 | 0.358209 | 26 | 0.235294 | 0.585366 | 0.384615 | 0.750000 |
| 2 | 試合日1_スペイン_コートジボワール | スペイン | left | WIN | 14 | 28 | 42 | 29 | 14 | 17 | 7 | 5 | 34 | 64 | 23 | 35 | 11 | 29 | 15 | 22 | 0.617188 | 0.187472 | 0.343750 | 16 | 0.466667 | 0.657143 | 0.379310 | 0.681818 |
| 3 | 試合日2_オーストラリア_ドイツ | ドイツ | right | WIN | 5 | 20 | 25 | 18 | 19 | 12 | 9 | 3 | 31 | 61 | 20 | 31 | 11 | 30 | 12 | 15 | 0.598361 | 0.150754 | 0.245902 | 22 | 0.185185 | 0.645161 | 0.366667 | 0.800000 |
| 4 | 試合日2_レバノン_カナダ | レバノン | left | LOSE | 6 | 10 | 16 | 19 | 18 | 22 | 12 | 1 | 30 | 62 | 22 | 43 | 8 | 19 | 5 | 5 | 0.548387 | 0.255220 | 0.080645 | 24 | 0.200000 | 0.511628 | 0.421053 | 1.000000 |
相関分析
それでは相関分析をしていきます。勝敗(RESULT)がそのままではWINとLOSEで相関係数を計算できないので、WINの場合は1、LOSEの場合は0としておきます。
eda_df = team_df.clone().with_columns(
RESULT_INT = pl.col("RESULT").map_dict({"WIN": 1, "LOSE": 0})
)
次に、勝敗と比較するスタッツを指定します。シュートを決めた本数や、合計リバウンド、2PTと3PTの合計試投数と相関係数を取ってもあまり示唆は得られないので、それ以外のスタッツを指定します。※要は、できるだけ結果そのものというよりはチームの能力を表していそうなスタッツを見ることにします。
feature_cols = [
'OREB', # オフェンスリバウンド
'DREB', # ディフェンスリバウンド
'AST', # アシスト
'PF', # ファール
'TO', # ターンオーバー
'ST', # スティール
'BLK', # ブロック
'2PTS_ATTEMPT', # 2ポイントの試投数
'3PTS_ATTEMPT', # 3ポイントの試投数
'FT_ATTEMPT', # フリースローの試投数
'eFG%', # efficient Field Goal Percentage(Four Factors)
'TO%', # Turn Over Percentage (Four Factors)
'FTR', # Free Throw Rate (Four Factors)
'OREB%', # Offensive Rebound Percentage (Four Factors)
'2PTS%', # 2ポイント成功率
'3PTS%', # 3ポイント成功率
'FT%', # フリースロー成功率
]
corr_cols = feature_cols + [`RESULT_INT`]
相関係数のヒートマップを表示させます。赤いほど相関係数が高く、青いほど相関係数が低く表示されています。
corr_df = (eda_df[corr_cols]
.corr()
.with_columns(INDEX_COL=pl.Series(corr_cols))
.to_pandas()
.set_index("INDEX_COL")
)
plt.figure(figsize=(12, 8))
sns.heatmap(corr_df, cmap="coolwarm", annot=True, fmt=".2f")
plt.show()

一番下の行のRESULT_INTを見ると、いわゆるミスのTO・TO%や自分たちにペナルティを与えられるPF が青いので、この数値が大きいほど相関係数が低い(→敗北につながっている)ことや、相手にセカンド・チャンスを与えないDREBや効率よくシュートを決められているかを示すeFG%・2PTS%・'3PT%'が赤いので、この数値が大きいほど相関係数が高い(→勝利につながっている)傾向が見て取れます。
なんとなく肌感に合っているような結果が得られました。
可視化分析
次に、もう少し生データに近い形で、箱ひげ図を使って勝利した場合と敗北した場合のスタッツを比較していきます。
概観
n_rows = 5 n_cols = 4 fig, axes = plt.subplots(nrows=n_rows, ncols=n_cols, figsize=(20, 20), tight_layout=True) for idx, col in enumerate(feature_cols): i = idx // n_cols j = idx % n_cols sns.boxplot(x=col, y="RESULT", data=eda_df.to_pandas(), ax=axes[i, j]) axes[i, j].set_title(f"{col} x RESULT") plt.show()

まずは一気にプロットして概観を把握してみます。先程の相関分析で値が大きい/小さかったスタッツほど、勝敗でデータの分布が分かれていそうです。 気になったものについて拡大して見ていきます。
オフェンスリバウンド

まずはオフェンスリバウンドです。こちらは意外と勝敗では差がついていなさそうです。これは、(今回のワールドカップにおいては)セカンドチャンスを頑張るよりも、以下に効率よくシュートを決められるかの方が重要だったということかもしれません。
ディフェンスリバウンド

次にディフェンスリバウンドです。こちらは逆に明らかに勝利チームの方が上回っていそうです。相手にセカンド・チャンスを与えず、自分たちのオフェンスにつなげる事が重要だということを物語っていそうです。
シュートの試投数


次に2ポイントと3ポイントの試投数ですが、ほぼ差が見られないとはいえ、敗北チームのほうがやや2ポイントの試投数が多く、勝利チームの方がやや3ポイントの試投数が多いようです。このあたりは、日本がフォーカスしていた3ポイントの重要性を示しているのかもしれません。
Four Factors




最後にFour Factorsについてまとめて見てみます。相関分析でもわかっていましたが、やはりeFG%で差がついているのが見て取れます(勝利チームの中央値は約60%、敗北チームの中央値は約50%)。
また、オフェンスリバウンドの実績値で見た際にはそんなに差がついていませんでしたが、相手チームとの相対感を示すOREB%では差が生じています。オフェンスリバウンドが多い = シュートをよく外しているという場合もありうるので、実績値で見ると差がつかない場合もあるということかもしれません。反対に、相手にディフェンスリバウンドを取らせず、自分たちがオフェンスリバウンドを取れているか?という指標であるOREB%だと差がよく出てくるということで、この辺がFour Factorsがゲームの分析に優れた指標であると言われている部分なのかなと思いました。
まとめ
比較的単純な相関分析・可視化を通して勝敗との相関が高い/低いスタッツや、勝敗チーム間のスタッツの違いを見てきました。ミスしない・シュートを効率よく決める・リバウンドを制するといったごく当たり前のことを出来たチームが勝っているという、ある種当たり前のことではありますが、定量的な傾向として見て取ることが出来ました。
また、Four Factorsを見ることで、より先鋭的にゲームを評価できそうな部分も見られました。
次回以降は、もうすこし機械学習や統計的な分析手法を使って深掘り分析した結果をまとめていきます。