Python+Seleniumを使ったスクレイピングその1(2023年10月時点)
今回はスクレイピングに関するメモです。Pythonでスクレイピングするといえば、urllib+BeautifulSoupがよく検索で出てきますが、最近のwebページはJavaScriptによってレンダリングされていることが多く、うまくスクレイピングできません。
そこで、Seleniumというブラウザ(ChromeとかFireFoxとか)の自動操作用ライブラリを活用することで、上記の問題をうまくかわしてスクレイピングを行うことができます。数年ぶりに久しぶりに使おうとしたら色々と状況が変わっていたので備忘録として使い方を残しておきます。ついでに、Ajaxなどを使った、動的なwebページに対応するための待機処理に関するTipsもまとめておきます。なお、今回もWindows環境が前提です。
なお、スクレイピング自体が著作権・サーバーへの負荷等の問題が生じうる行為なので、ルール・マナーを守った運用が必要です。自分への戒めも兼ねて、注意事項として記載しておきます。
Seleniumについて、状況が変わっていたこと
数年前の時点ではSeleniumを扱う際に、以下のように別のものをインストールする必要があり、ハマることが多かったです。
- Chromeを使いたい→Seleniumとは別に、chromedriverのインストールが必要
- Seleniumを使う際に、操作するブラウザが表示されないようにしたい→Seleniumとは別にPhantomJSが必要
しかし、最近バージョンアップされたSeleniumではそれ単体で上記のやりたいことを実現できるようになっていました。今回は4.14.0のバージョンのSeleniumを使って、実際に試していきます。
使い方その1|基本的な使い方
まずはライブラリをインポートします。
from selenium import webdriver from selenium.webdriver.chrome.options import Options from selenium.webdriver.common.by import By
インポートした後は、次のようにコードを記述することで、スクレイピングを行うことができます。 今回はPythonの公式ページにアクセスしてみます。
# アクセスしたいURLを指定 url = "http://www.python.org" # ブラウザを操作するためのwebdriverを設定 options = Options() options.add_argument("--headless") # このオプション設定により、ブラウザが表示されなくなる driver = webdriver.Chrome(options=options) # chromedriverを別でインストールする必要なし # ブラウザを起動し、URLにアクセス driver.get(url) # HTMLの要素を取得 elem = driver.find_element(By.CSS_SELECTOR, "div.introduction") print(elem.text) # ブラウザを閉じる driver.close()
# 実行結果 Python is a programming language that lets you work quickly and integrate systems more effectively. Learn More
Pythonの公式ページにアクセスし、要素を取得できていることが確認できました。
使い方その2|待機処理を意識した使い方
Ajaxを利用したJavaScriptのレンダリングなどがある場合、URLにアクセスしてから(あるいは何かしらSeleniumでwebページの操作を行ってから)HTMLの要素が全てレンダリングされるまでに時間がかかることがあります。
※もちろん、JavaScript以外の理由として、ネット回線の速度やサーバー側の負荷が問題になる場合もあります。
time.sleep(5) など、URLにアクセスしてから要素を取得するまでの間に明示的に待ち時間を設けることも可能ですが、待ち時間が不十分でレンダリングが間に合わずに要素の取得時にエラーとなってしまったり、逆にレンダリングがすぐに終わってしまい、無駄な時間がかかってしまう恐れがあります。
そこで、WebDriverWaitとexpected_conditionsを活用することで上記の問題を解決しながらスクレイピングを行うことが可能になります。
それでは、基本的な使い方のときと同様に、まずは必要なライブラリをインポートします。
from selenium import webdriver from selenium.webdriver.chrome.options import Options from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait # 追加 from selenium.webdriver.support import expected_conditions as EC # 追加
WebDriverWaitとexpected_conditionsを利用して、先程のコードを書き直してみます。横にコメントが記載されている行が変更点です。
# アクセスしたいURLを指定 url = "http://www.python.org" # ブラウザを操作するためのwebdriverを設定 options = Options() options.add_argument("--headless") driver = webdriver.Chrome(options=options) wait = WebDriverWait(driver=driver, timeout=30) # 最大待ち時間の設定 # ブラウザを起動し、URLにアクセス driver.get(url) wait.until(EC.presence_of_all_elements_located) # HTMLの要素が全てレンダリングされるまで待つ # HTMLの要素を取得 elem = driver.find_element(By.CSS_SELECTOR, "div.introduction") print(elem.text) # ブラウザを閉じる driver.close()
# 実行結果 Python is a programming language that lets you work quickly and integrate systems more effectively. Learn More
問題なく動作していることを確認できました!
要素の取得方法について、更に詳細は次の記事でメモしておきます。
参考にさせていただいた記事
- https://qiita.com/memakura/items/20a02161fa7e18d8a693
- https://selenium-python.readthedocs.io/getting-started.html#simple-usage
- https://yuki.world/python-selenium-quickest-setup/
- https://www.harubears.com/ja/tech-ja/how-to-enable-headlesschrome-with-python/
- https://office54.net/python/scraping/selenium-wait-time
pyenv+venv+PoetryによるPython環境構築(2023年10月時点)
PCの買い替えの際などに環境構築に手間取ることが多いので、備忘録としてまとめておきます。 パッケージ管理ツールとしてはpipやcondaなどもありますが、最近トレンドらしいpyenv+venv+Poetryのやり方が一番馴染みやすかったです。
前提として、Windows+PowerShellでの環境構築をしていきます。
Pythonのインストール
公式のサイトに従って、Pythonをインストールします。この辺は他にも参考になる記事が沢山あるので詳細は割愛します。
pyenv+venvによる仮想環境の構築
仮想環境を構築したいディレクトリに移動しておきます。
PS D:\workspace> cd my_dir
pyenvでインストールできるpythonのバージョンを確認します。
PS D:\workspace\my_dir> pyenv install -l :: [Info] :: Mirror: https://www.python.org/ftp/python 2.4-win32 2.4.1-win32 2.4.2-win32 2.4.3c1-win32 ... 3.11.3 3.11.4-arm 3.11.4-win32 3.11.4 3.12.0a1-win32 3.12.0a1-arm 3.12.0a1
今回は3.11.4をインストールし、my_dir内の仮想環境用に設定します。
PS D:\workspace\my_dir> pyenv install 3.11.4 :: [Info] :: Mirror: https://www.python.org/ftp/python PS D:\workspace\my_dir> pyenv local 3.11.4 PS D:\workspace\my_dir> pyenv versions 3.10.5 * 3.11.4 (set by D:\workspace\my_dir\.python-version)
次に、venvで仮想環境を作っていきます。今回、環境名はmyenvとしておきます。 仮想環境を作ったあとは、アクティベートしていきます。アクティベートされると、左端に環境名が表示されます。
PS D:\workspace\my_dir> python -m venv myenv # 仮想環境の作成 PS D:\workspace\my_dir> .\myenv\Scripts\Activate.ps1 # アクティベート (myenv) PS D:\workspace\my_dir>
- ※権限がないとエラーが出た場合は、事前に
Set-ExecutionPolicy -ExecutionPolicy RemoteSigned -Scope Processを実行するようにします。 - ※PowrShellでなくCmdを使う場合は、
./myenv/Scripts/Activate.batでアクティベートできます。 - ※以下、#の後はコメントなので、実際にコマンドを打つ際には不要です。
これで仮想環境のとりあえずの構築完了です。
Poetryによるライブラリのインストール
まずはPoetryをインストールしていきます。
(myenv) PS D:\workspace\my_dir> python -m pip install --upgrade pip # pipのアップグレード (myenv) PS D:\workspace\my_dir> pip install -U pip setuptools # 念のため、pipとsetuptoolsをアップグレード (myenv) PS D:\workspace\my_dir> pip install poetry # poetryをインストール
インストールが終わったら、初期化します。 色々とコンソール上で聞かれていきますが、基本的にはデフォルトでOKです。(Enterボタンを連打すればOK)
(myenv) PS D:\workspace\my_dir> poetry init
次に、必要なライブラリをインストールしていきます。poetry add [ライブラリ名] でインストールできます。
今回は、今後の記事で使うことが多そうなライブラリ一式をダウンロードしておきます。
ちなみに、インストールされたライブラリの一覧は、pyproject.tomlで管理されています。もし、新しく環境構築をする必要が出た場合は、このpyproject.tomlを同じディレクトリに置いた状態で、poetry install とコマンドを打つと、いちいちaddしなくても一括でライブラリがインストールされます。
(myenv) PS D:\workspace\my_dir> poetry add jupyterlab ipywidgets ipykernel black # Jupyter Notebook系 (myenv) PS D:\workspace\my_dir> poetry add matplotlib japanize-matplotlib seaborn # 可視化系 (myenv) PS D:\workspace\my_dir> poetry add lightgbm scikit-learn statsmodels polars "pandas<2.1.1" "numpy<1.26.0" pyarrow shap # データ分析系 (myenv) PS D:\workspace\my_dir> poetry add selenium tqdm # その他系
- ※
numpyやpandasは依存関係的にエラーが起きやすいので、"numpy<1.26.0" のようにバージョンまで指定する必要が出ることが多いです。 - ※ライブラリを削除する場合は、
poetry remove [ライブラリ名]です。
以上でライブラリのインストールができました!
Jupyter Notebookで動作確認
Visual Studio Codeを立ち上げ、Jupyter Notebookファイルを作成します。(Visual Studio Codeについても素晴らしい参考記事が沢山あるので割愛します。)
Visual Studio Codeに仮想環境を認識してもらうため、左上のFile > Open Folderから今回仮想環境を構築したディレクトリを選んで開いておきます。
さらにNew Fileから、hello_world.ipynbを作成し、開きます。
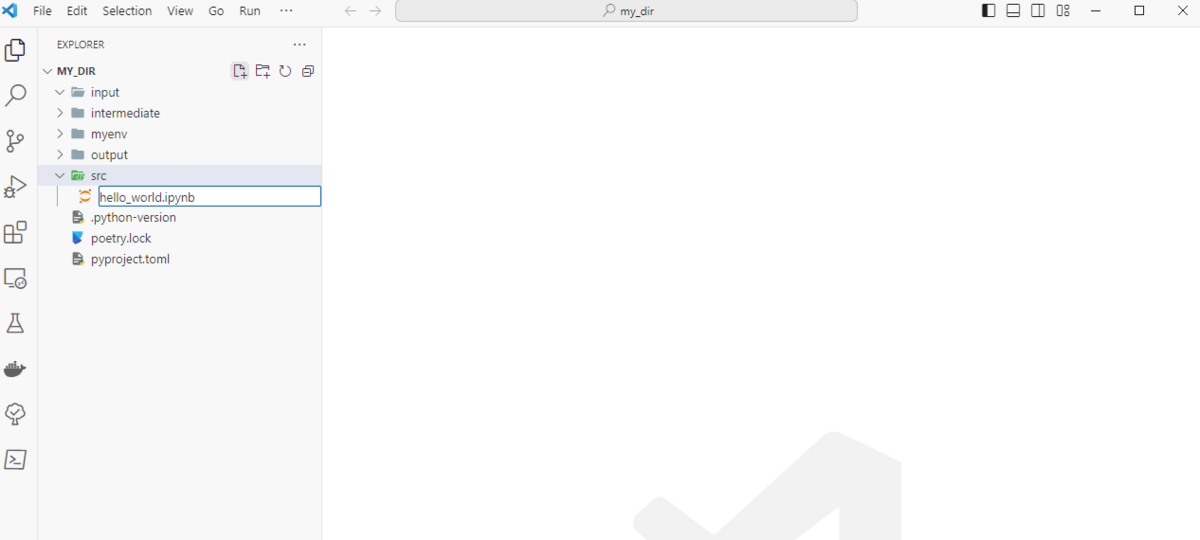
開いたJupyter Notebookファイル右上のSelect Kernel > Python Environmentsを選択すると、選べる仮想環境一覧が出てくるので、今回構築したmyenvを選びます。(Recommendedと表示されているはずです。)

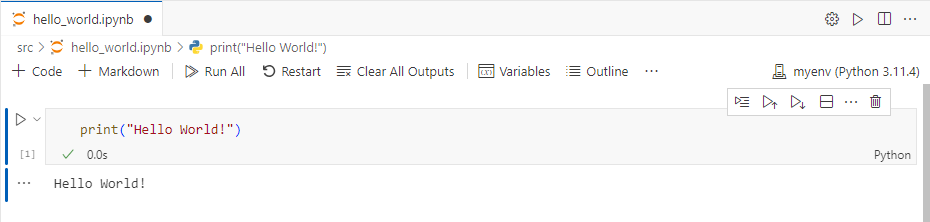
print("Hello World!")
と打ち込み、実行してHello World!と表示されたら成功です!