FIBA Basketball World Cup 2023をデータ分析してみた(Part.4|次元削減分析(主成分分析・t-SNE・UMAP))
本記事は、全5回に分けてFIBAバスケットボールワールドカップ2023の全92試合を分析してみたシリーズ第4回目です。
- 相関分析・可視化分析|勝敗と相関が高いスタッツの項目は何か?勝利したチームと敗北したチームのスタッツの差はどう違うのか?
- 決定木分析|勝利するチームのスタッツの条件は?(その1)
- LightGBM+SHAP分析|勝利するチームのスタッツの条件は?(その2)
- 次元削減分析(主成分分析・t-SNE・UMAP)|スタッツから見る大会参加チームの特徴は?(その1)
- 因子分析+クラスタリング|スタッツから見る大会参加チームの特徴は?(その2)
前回・前々回は、決定木分析やLightGBM+SHAP分析を行い、勝利する際のスタッツの条件を探ってみました。 bballdatanote.hatenablog.com
今回は主成分分析やt-SNE、UMAPなどの手法を用いて各チームのスタッツを2次元に落とし込み、プロットしてみることで、大会の参加チームの特徴がうまく分かれそうか?そして、日本はどのチームに似ていたのかを分析してみたいと思います。
目次は次の通りです。
データの準備・前処理
毎回同様、大会公式サイトのデータを用いて、以下のように試合別・チーム別のデータに集約していきます。また、追加スタッツとしてFour FactorsとField Goal Percentageも出しておきます。
team_df.head()
| GAME_KEY | TEAM | GAME_POSITION | RESULT | OREB | DREB | REB | AST | PF | TO | ST | BLK | FG_MADE | FG_ATTEMPT | 2PTS_MADE | 2PTS_ATTEMPT | 3PTS_MADE | 3PTS_ATTEMPT | FT_MADE | FT_ATTEMPT | eFG% | TO% | FTR | DREB_OPPOSITE | OREB% | 2PTS% | 3PTS% | FT% | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 試合日1_ドイツ_日本 | 日本 | right | LOSE | 6 | 24 | 30 | 17 | 16 | 12 | 5 | 3 | 23 | 65 | 17 | 30 | 6 | 35 | 11 | 17 | 0.400000 | 0.142045 | 0.261538 | 36 | 0.142857 | 0.566667 | 0.171429 | 0.647059 |
| 1 | 試合日1_南スーダン_プエルトリコ | 南スーダン | left | LOSE | 8 | 27 | 35 | 23 | 23 | 19 | 9 | 5 | 34 | 67 | 24 | 41 | 10 | 26 | 18 | 24 | 0.582090 | 0.196769 | 0.358209 | 26 | 0.235294 | 0.585366 | 0.384615 | 0.750000 |
| 2 | 試合日1_スペイン_コートジボワール | スペイン | left | WIN | 14 | 28 | 42 | 29 | 14 | 17 | 7 | 5 | 34 | 64 | 23 | 35 | 11 | 29 | 15 | 22 | 0.617188 | 0.187472 | 0.343750 | 16 | 0.466667 | 0.657143 | 0.379310 | 0.681818 |
| 3 | 試合日2_オーストラリア_ドイツ | ドイツ | right | WIN | 5 | 20 | 25 | 18 | 19 | 12 | 9 | 3 | 31 | 61 | 20 | 31 | 11 | 30 | 12 | 15 | 0.598361 | 0.150754 | 0.245902 | 22 | 0.185185 | 0.645161 | 0.366667 | 0.800000 |
| 4 | 試合日2_レバノン_カナダ | レバノン | left | LOSE | 6 | 10 | 16 | 19 | 18 | 22 | 12 | 1 | 30 | 62 | 22 | 43 | 8 | 19 | 5 | 5 | 0.548387 | 0.255220 | 0.080645 | 24 | 0.200000 | 0.511628 | 0.421053 | 1.000000 |
また、今回はプロットする際の参考情報として大会の順位も使うことにします。
rank_df.head()
さらに、これまではチーム別・試合別の粒度でデータを扱ってきましたが、今回はチーム別の粒度で分析します。また、次元削減分析を行うにあたっては、標準化をかけて各スタッツのスケールを合わせておきます(より適切に次元削減を行い、解釈しやすくするため)。そのため、以下のような前処理を行っていきます。
# 実数系(割合ではない)スタッツ basic_stats_cols = [ 'OREB', 'DREB', 'REB', 'AST', 'PF', 'TO', 'ST', 'BLK', 'FG_MADE', 'FG_ATTEMPT', '2PTS_MADE', '2PTS_ATTEMPT', '3PTS_MADE', '3PTS_ATTEMPT', 'FT_MADE', 'FT_ATTEMPT', 'DREB_OPPOSITE', ]
# チームごとに実数系のスタッツの試合平均を取る summary_team_df = team_df.group_by("TEAM").agg(pl.mean(basic_stats_cols)) # シュート成功率等の割合系のスタッツを計算 summary_team_df = process_team_stats(summary_team_df, key_cols=["TEAM"]) # 大会の最終順位と突合し、国名に最終順位を結合(可視化用に利用) summary_team_df = summary_team_df.join( rank_df, on="TEAM", how="left" ).with_columns( TEAM_LABEL=pl.col("RANK").cast(str) + "_" + pl.col("TEAM") ).sort( "RANK" ).to_pandas() # 次元削減用に標準化 scale_cols = [col for col in summary_team_df.columns if not col in ["TEAM_LABEL", "TEAM", "RANK"]] # 標準化する対象のスタッツの一覧 scaler = ColumnTransformer([ ("Standard Scaler", StandardScaler(), scale_cols) ]) scaler.fit(summary_team_df[scale_cols]) summary_team_df[scale_cols] = scaler.transform(summary_team_df[scale_cols]) summary_team_df.head()
| TEAM | OREB | DREB | REB | AST | PF | TO | ST | BLK | FG_MADE | ... | DREB_OPPOSITE | eFG% | TO% | FTR | OREB% | 2PTS% | 3PTS% | FT% | RANK | TEAM_LABEL | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | ドイツ | -0.357255 | 0.654719 | 0.281435 | 0.767749 | -0.728020 | -1.242350 | 0.747780 | -0.651354 | 1.302677 | ... | -1.282535 | 1.265120 | -1.173782 | -0.376622 | 0.353542 | 1.389546 | 0.742347 | 0.727326 | 1 | 1_ドイツ |
| 1 | セルビア | -1.111176 | 0.213180 | -0.522665 | 1.171533 | -1.289234 | -1.378872 | 1.539473 | 0.057603 | 1.384190 | ... | -1.779762 | 1.705373 | -1.193995 | 0.922567 | -0.148243 | 2.132540 | 0.676955 | 0.596071 | 2 | 2_セルビア |
| 2 | カナダ | 0.739356 | 0.102796 | 0.535361 | 0.678020 | -0.104448 | -0.969306 | 0.351933 | -0.415035 | 1.343433 | ... | -0.835031 | 1.201705 | -1.224908 | 0.878006 | 1.096495 | 0.787233 | 1.174016 | 0.484411 | 3 | 3_カナダ |
| 3 | アメリカ合衆国 | -0.288717 | 2.200104 | 1.508746 | 1.261262 | -0.915091 | 0.395914 | 1.440512 | 2.420790 | 2.362344 | ... | -0.735585 | 1.481867 | -0.190144 | 1.239070 | 0.116469 | 1.307604 | 1.113105 | 0.795034 | 4 | 4_アメリカ合衆国 |
| 4 | ラトビア | -1.590943 | -0.228358 | -1.157481 | 1.440722 | 0.207337 | -1.651916 | -0.736646 | -0.060557 | 1.139651 | ... | -0.835031 | 1.693414 | -1.281602 | -1.751610 | -1.183893 | 1.218891 | 1.526417 | -0.100256 | 5 | 5_ラトビア |
5 rows × 27 columns
次元削減分析
それでは、実際に次元削減分析を行っていきます。今回試すのは、主成分分析(PCA)・t-SNE・UMAP、そして主成分分析(PCA)+UMAPの2段階で次元削減を行うパターンの計4種類です。※参考記事は最後に載せています。
なお、UMAPは事前にインストールしておきます。
poetry add umap
関数の準備
似たようなことを繰り返し行うため、予め関数として定義しておきます。なお、主成分分析(PCA)のみは線形的なアルゴリズムのため、各スタッツに係数(ローディング)を乗じて足したものが次元削減後の値となるため、係数(ローディング)を表示させるようにしておきます。他のアルゴリズムは非線形的なアルゴリズムのため、別のやり方で元のスタッツと次元削減後の値の関係性を考察するようにします。
# ライブラリのインポート # 可視化系 import matplotlib.pyplot as plt import seaborn as sns import japanize_matplotlib %matplotlib inline # 特徴量エンジニアリング・モデル評価系 from sklearn.compose import ColumnTransformer from sklearn.preprocessing import StandardScaler # 次元圧縮系 from sklearn.decomposition import PCA from sklearn.manifold import TSNE from umap import UMAP
# 次元削減対象のスタッツ feature_cols = [ 'OREB', 'DREB', 'AST', 'PF', 'TO', 'ST', 'BLK', '2PTS_ATTEMPT', '3PTS_ATTEMPT', 'FT_ATTEMPT', 'eFG%', 'TO%', 'FTR', 'OREB%', '2PTS%', '3PTS%', 'FT%', ]
次元削減用のサブ関数(ここをクリックすると表示されます)
# 次元削減モデルを設定する def embedding_models(model_name, N): embedding_model_dict = { "PCA": PCA(n_components=N, random_state=0), "tSNE": TSNE(n_components=N, random_state=0), "UMAP": UMAP(n_components=N, random_state=0) } return embedding_model_dict[model_name] # 実際に次元削減を行い、結果として次元削減モデルと次元削減後の結果を返す def embedding(X, model_name, N, embedded_cols, label_txt): model = embedding_models(model_name, N) X_embedded = model.fit_transform(X) embedded_df = ( pl.DataFrame(X_embedded, schema=embedded_cols) .with_columns(TEAM_LABEL=pl.lit(label_txt)) ) return model, embedded_df.to_pandas() # 次元削減した結果をプロットする def plot_embedded_space(model_name, embedded_df, size): print("次元削減空間の可視化") plt.figure(figsize=(12, 8)) sns.scatterplot(x="embedded_1", y="embedded_2", data=embedded_df, hue=embedded_df["TEAM_LABEL"], size=size, palette=sns.color_palette("coolwarm", 32), sizes=(20, 200)) for x, y, txt in zip(embedded_df["embedded_1"], embedded_df["embedded_2"], embedded_df["TEAM_LABEL"]): plt.text(x, y, txt, size=10) plt.title(f"Emmbedding Space {model_name}") plt.xlabel("embedded_1") plt.ylabel("embedded_2") plt.legend(embedded_df["TEAM_LABEL"], loc='center left', bbox_to_anchor=(1., .5)) plt.show() # 次元削減した結果をチームごとに棒グラフで表示する def show_embedded_score(embedded_df, embedded_cols): embedded_df = pl.from_pandas(embedded_df)[["TEAM_LABEL"]+embedded_cols] print("スコア") display(embedded_df) plt.figure(figsize=(6, 20)) embedded_df = embedded_df.melt(id_vars="TEAM_LABEL", value_vars=embedded_cols).to_pandas() sns.barplot(x="value", y="TEAM_LABEL", data=embedded_df, hue="variable", palette=sns.color_palette("deep")) plt.axvline(x=0, color="lightgray", linestyle="--") plt.show() # (PCAのみ)次元削減した結果と各スタッツの関係性(係数/ローディング)を表示・プロットする def show_loading(model, feature_cols, embedded_cols): loading_df = pd.DataFrame(model.components_.T, index=feature_cols, columns=embedded_cols) x_col = embedded_cols[0] y_col = embedded_cols[1] print("ローディング") display(loading_df) plt.figure(figsize=(8, 8)) sns.scatterplot(x=x_col, y=y_col, data=loading_df) for x, y, txt in zip(loading_df[x_col], loading_df[y_col], loading_df.index): plt.text(x, y, txt, size=10) plt.show() # (PCA以外)次元削減した結果と、各スタッツの関係性を相関係数、散布図で可視化する def plot_embedded_score_vs_features(summary_team_df, embedded_df, feature_cols, embedded_cols): tmp_df = embedded_df.merge(summary_team_df, on="TEAM_LABEL", how="left") n_rows = 5 n_cols = 4 for embedded in embedded_cols: # 相関係数 corr_cols = feature_cols + [embedded] corr_df = (pl.from_pandas(tmp_df[corr_cols]) .corr() .with_columns(INDEX_COL=pl.Series(corr_cols)) .to_pandas() .set_index("INDEX_COL") ) plt.figure(figsize=(12, 8)) sns.heatmap(corr_df, cmap="coolwarm", vmin=-1, vmax=1, square=True, annot=True, fmt=".2f") plt.show() # 散布図で可視化 fig, axes = plt.subplots(nrows=n_rows, ncols=n_cols, figsize=(24, 24), tight_layout=True) for idx, feature in enumerate(feature_cols): i = idx // n_cols j = idx % n_cols sns.scatterplot(x=feature, y=embedded, data=tmp_df, hue=tmp_df["TEAM_LABEL"], palette=sns.color_palette("coolwarm", 32), ax=axes[i, j]) for x, y, txt in zip(tmp_df[feature], tmp_df[embedded], tmp_df["TEAM_LABEL"]): axes[i, j].text(x, y, txt, size=8) axes[i, j].set_title(f"{embedded} X {feature}") axes[i, j].get_legend().remove() plt.show() print("-"*100)
次元削減用のメイン関数(ここをクリックすると表示されます)
# 実際に次元削減、可視化を行っていく(PCA・t-SNE・UMAP用) def summary_embedding(summary_team_df, model_name, N, feature_cols, label_col, size_col): X = summary_team_df[feature_cols] label_txt = summary_team_df[label_col].to_list() size = summary_team_df[size_col].to_list() embedded_cols = [f"embedded_{i+1}" for i in range(N)] # 次元削減 model, embedded_df = embedding(X=X, model_name=model_name, N=N, embedded_cols=embedded_cols, label_txt=label_txt) # 次元削減後の可視化 plot_embedded_space(model_name=model_name, embedded_df=embedded_df, size=size) print("#"*200) # 次元削減結果のスコアの可視化 show_embedded_score(embedded_df=embedded_df, embedded_cols=embedded_cols) print("#"*200) # スコアと特徴量の可視化(PCAの場合はローディング、それ以外は相関係数+散布図) if model_name == "PCA": show_loading(model=model, feature_cols=X.columns, embedded_cols=embedded_cols) else: plot_embedded_score_vs_features(summary_team_df=summary_team_df, embedded_df=embedded_df, feature_cols=feature_cols, embedded_cols=embedded_cols) print("#"*200) # 実際に次元削減、可視化を行っていく(PCA+UMAP用) def summary_embedding_pca_umap(summary_team_df, model_name, pca_N, umap_N, feature_cols, label_col, size_col): X = summary_team_df[feature_cols] label_txt = summary_team_df[label_col].to_list() size = summary_team_df[size_col].to_list() pca_embedded_cols = [f"embedded_{i+1}" for i in range(pca_N)] embedded_cols = [f"embedded_{i+1}" for i in range(umap_N)] # 次元削減 pca_model, pca_embedded_df = embedding(X=X, model_name="PCA", N=pca_N, embedded_cols=pca_embedded_cols, label_txt=label_txt) model, embedded_df = embedding(X=pca_embedded_df[pca_embedded_cols], model_name="UMAP", N=umap_N, embedded_cols=embedded_cols, label_txt=label_txt) # 次元削減後の可視化 plot_embedded_space(model_name=model_name, embedded_df=embedded_df, size=size) print("#"*200) # 次元削減結果のスコアの可視化 show_embedded_score(embedded_df=embedded_df, embedded_cols=embedded_cols) print("#"*200) # スコアと特徴量の可視化(PCAの場合はローディング、それ以外は相関係数+散布図) if model_name == "PCA": show_loading(model=model, feature_cols=X.columns, embedded_cols=embedded_cols) else: plot_embedded_score_vs_features(summary_team_df=summary_team_df, embedded_df=embedded_df, feature_cols=feature_cols, embedded_cols=embedded_cols) print("#"*200)
それでは、実際に次元削減を行っていきます。
主成分分析(PCA)
まずは主成分分析(PCA)からです。
summary_embedding(
summary_team_df=summary_team_df,
model_name="PCA",
N=2,
label_col="TEAM_LABEL",
size_col="RANK",
feature_cols=feature_cols
)
次元削減空間の可視化
 なんとなく右側が下位チーム、左側が上位チームに分かれています。左上のラトビアと左下のアメリカ合衆国は特徴的なものがあるのでしょうか。
なんとなく右側が下位チーム、左側が上位チームに分かれています。左上のラトビアと左下のアメリカ合衆国は特徴的なものがあるのでしょうか。
日本はドイツ・フィンランド・ブラジルと近い場所にプロットされていますね。次に、次元削減後のスコア(embedded_1とembedded_2)を棒グラフでもプロットしてみます。
次元削減結果のスコアの可視化

先程の散布図の例を棒グラフとして表示しただけです。上位チームだと青色のembedded_1はマイナス、下位チームだとマイナスとなっている傾向であることが見て取れます。更に、各スコアの意味を解釈していきます。
スコアと特徴量の可視化(PCAの場合なのでローディング)
係数の実際の値は次の通りです。
| embedded_1 | embedded_2 | |
|---|---|---|
| OREB | 0.221202 | -0.216115 |
| DREB | -0.179890 | -0.375490 |
| AST | -0.385786 | -0.059124 |
| PF | 0.287357 | 0.064920 |
| TO | 0.178229 | -0.264742 |
| ST | 0.077950 | -0.143391 |
| BLK | -0.177066 | -0.332815 |
| 2PTS_ATTEMPT | 0.191240 | -0.240046 |
| 3PTS_ATTEMPT | -0.167807 | 0.243864 |
| FT_ATTEMPT | 0.031401 | -0.425537 |
| eFG% | -0.451049 | -0.080173 |
| TO% | 0.147900 | -0.179360 |
| FTR | 0.016320 | -0.408268 |
| OREB% | 0.016784 | -0.267625 |
| 2PTS% | -0.395949 | -0.158122 |
| 3PTS% | -0.368141 | 0.045435 |
| FT% | -0.184991 | 0.032140 |
さらに散布図にプロットしてみます。

どうやら、主成分分析(PCA)においては、
- embedded_1|PF・OREB・2PTS_ATTEMPTが多いほど値が大きくなる。逆に、eFG%・2PTS%・3PTS%・ASTが多いほど値が小さくなるといった特徴があるようです。要は、アシストが多く、効率良くシュートを打てているかを示していそうです。
- 最もこのスコアが小さかったセルビアが、一番チームプレーで効率的なシュートを打てていたのかもしれません。 -embedded_2|3PTS_ATTEMTが多いほど値が大きくなる。逆に、FT_ATTEMPT・FTR・DREB・BLKが多いほど値が小さくなる傾向があるようです。解釈が分かれる所ではありますが、インサイドへのアタックが多いチームや、ディフェンスの際に中を固めているチームほど値が小さくなるようです。
- 最もこの値が小さかったアメリカはインサイドへのアタックを果敢に仕掛けていたり、速攻を繰り出そうとしていたはずなので、結果的にFT獲得数の面で一歩抜きん出ていたのかもしれません(FT_ATTEMPT|大会2位、FTR|大会3位)。また、身体能力も高いためか、ブロック数やDREBも多かったです(BLK|大会1位、DREB|大会1位)。
- インサイドの層が薄い印象でしたので、ブロック数とDREBに関しては少し意外な結果でした。※OREB|大会21位、OREB%大会16位なので、アメリカがインサイドのチームではないという感覚は間違ってなさそうです。
t-SNE
次に、t-SNEでの結果を見ていきます。
summary_embedding(
summary_team_df=summary_team_df,
model_name="tSNE",
N=2,
label_col="TEAM_LABEL",
size_col="RANK",
feature_cols=feature_cols
)
次元削減空間の可視化
 なんとなく上に上位チーム、下に下位チームが来る結果となりました。
なんとなく上に上位チーム、下に下位チームが来る結果となりました。
日本は主成分分析(PCA)同様にドイツ・ブラジル・フィンランド、更にスロベニアが近いチームとなっています。また、やはりアメリカとラトビア、更にはアンゴラは少し外れた位置におり、特徴的なチームだったように見えます。
次元削減結果のスコアの可視化
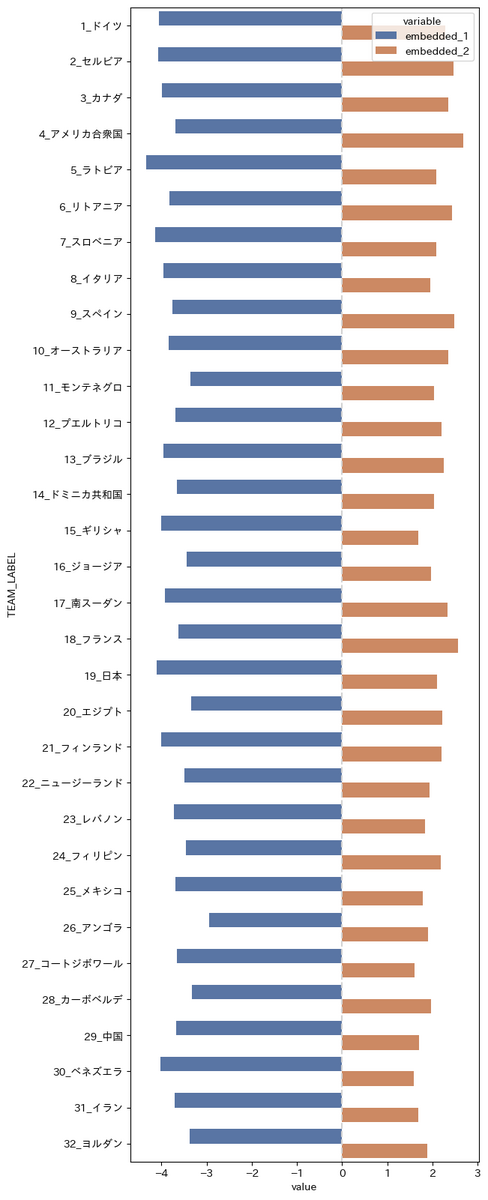 t-SNEの場合は棒グラフで可視化してもぱっとは何を言えるかは分からなさそうです。
t-SNEの場合は棒グラフで可視化してもぱっとは何を言えるかは分からなさそうです。
スコアと特徴量の可視化
スコアと各スタッツ(特徴量)の相関係数と、散布図を見ていきます。
embedded_1


embedded_1については、2PTS_ATTEMPTやOREBが高いと値が高く、eFG%や3PTS%・ASTが低いと値が(比較的)低くなっていたようです。インサイド偏重なチームだとこのembedded_1が顕著に高く出ていたようです。
embedded_2


embedded_2については、DREBやBLK、eFG%や2PTS%が高いと値が高くなっていたようです。主成分分析同様、アメリカが一番上に位置づいているのも納得ですね。
UMAP
次に、UMAPでの結果を見ていきます。
summary_embedding(
summary_team_df=summary_team_df,
model_name="UMAP",
N=2,
label_col="TEAM_LABEL",
size_col="RANK",
feature_cols=feature_cols
)
次元削減空間の可視化
 UMAPだと左上側に上位チーム、右下側に下位チームが位置づきました。やはり、日本に近いチームとしてはブラジル・フィンランドが位置しています。
UMAPだと左上側に上位チーム、右下側に下位チームが位置づきました。やはり、日本に近いチームとしてはブラジル・フィンランドが位置しています。
次元削減結果のスコアの可視化
 UMAPもt-SNE同様、棒グラフとして可視化しても、ぱっとは特徴は分からなさそうです。
UMAPもt-SNE同様、棒グラフとして可視化しても、ぱっとは特徴は分からなさそうです。
スコアと特徴量の可視化
スコアと各スタッツ(特徴量)の相関係数と、散布図を見ていきます。
embedded_1


embedded_1については、ASTやeFG%、2PTS%が高いと値が低くなり、TO・TO%が多いと値が高くなっているようです。ミスが多いチームほど値が高くなっている→下位チームがプロットされているというのはある種納得の行く結果のように思えます。
embedded_2


embedded_2については、eFG%・2PTS%・3PTS%やASTが高いほど値が高くなっているので、効率的にシュートを打てているかどうかを表していそうです。上位のヨーロッパやアメリカのチームがプロットされているのもよくわかります。
主成分分析(PCA)+UMAP
最後に、主成分分析(PCA)+UMAPでの結果を見ていきます。これは、UMAPを行う前にPCAを行ったほうがより良い結果が得られることがあるらしいとのことで試してみました。
まずは、PCAでどのくらいまで次元削減しておくべきか、累積寄与率を見て確認しておきます。
# PCAの累積寄与率を確認 pca = PCA(n_components=15, random_state=0) X_embedded = pca.fit_transform(summary_team_df[feature_cols]) plt.plot(np.cumsum(pca.explained_variance_ratio_), '-o') plt.xlabel("principal components(PC1, PC2, ..,)") plt.ylabel("cumulative contribution rate") plt.grid() plt.show()
 10個もあればほぼ寄与率100%なので、PCAのn_componentsは10にしておきます。
10個もあればほぼ寄与率100%なので、PCAのn_componentsは10にしておきます。
summary_embedding_pca_umap(
summary_team_df=summary_team_df,
model_name="PCA_UMAP",
pca_N=10,
umap_N=2,
label_col="TEAM_LABEL",
size_col="RANK",
feature_cols=feature_cols
)
次元削減空間の可視化
 先程のUMAPと同様、左上に上位チーム、右下に下位チームがプロットされていそうです。ただし、今回はアメリカやラトビアが他の時ほど目立っている形ではなくなりました。また、日本に似ているチームとして、ブラジル・フィンランドの他にフランスも入ってきそうです。
先程のUMAPと同様、左上に上位チーム、右下に下位チームがプロットされていそうです。ただし、今回はアメリカやラトビアが他の時ほど目立っている形ではなくなりました。また、日本に似ているチームとして、ブラジル・フィンランドの他にフランスも入ってきそうです。
次元削減結果のスコアの可視化
 なんとなくではありますが、上位チームやヨーロッパ系、日本はembedded_1がマイナスとなっており、他の下位チームやアジア・アフリカ系のチームはプラスになっているように見受けられます。
なんとなくではありますが、上位チームやヨーロッパ系、日本はembedded_1がマイナスとなっており、他の下位チームやアジア・アフリカ系のチームはプラスになっているように見受けられます。
スコアと特徴量の可視化
スコアと各スタッツ(特徴量)の相関係数と、散布図を見ていきます。
embedded_1


今回もASTやeFG%・2PTS%・3PTS%が高いほどembedded_1が低くなっているため、これは効率よくシュートを打てているかを表していそうです。
embedded_2

 TOやTO%が多いと値が低くなっているため、ミスの多さを示す指標となっているようです。
TOやTO%が多いと値が低くなっているため、ミスの多さを示す指標となっているようです。
まとめ
様々な次元削減の方法を試しながら、各チームの特徴をマッピングしてみました。やはり上位チームは効率的なシュートを打てているということが改めてよくわかりました。また、日本は下位チームに位置していながらも上位チームのブラジルや、ヨーロッパのチームのフィンランドに似た傾向を取っており、確実に世界と戦うための戦い方を身につけつつあることが、今回の分析からも見て取れたように思えます。
次回は、今回の次元削減とは逆の考え方(スタッツをどうまとめるかではなく、スタッツがどの因子から生まれているか)を用いた、因子分析で今回と同様の分析を行っていきます。